存储引擎

查看可用引擎:
show engines;
查看表的相关信息:
SHOW TABLE STATUS LIKE 'fz_warn';
MyISAM存储引擎
1、大文件(达到63位文件长度)在支持大文件的文件系统和操作系统上被支持。
2、当把删除和更新及插入操作混合使用的时候,动态尺寸的行产生更少碎片。这要通过合并相邻被删除的块,以及若下一个块被删除,就扩展到下一块自动完成。
3、每个MyISAM表最大索引数是64,这可以通过重新编译来改变。每个索引最大的列数是16 4、NULL被允许在索引的列中,这个值占每个键的0~1个字节 5、可以把数据文件和索引文件放在不同目录(InnoDB是放在一个目录里面的)
InnoDB存储引擎
MySQL 默认的事务型存储引擎,只有在需要它不支持的特性时,才考虑使用其它存储引擎
1、InnoDB给MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。InnoDB锁定在行级并且也在SELECT语句中提供一个类似Oracle的非锁定读。这些功能增加了多用户部署和性能。在SQL查询中,可以自由地将InnoDB类型的表和其他MySQL的表类型混合起来,甚至在同一个查询中也可以混合
2、InnoDB是为处理巨大数据量的最大性能设计。它的CPU效率可能是任何其他基于磁盘的关系型数据库引擎锁不能匹敌的
3、InnoDB存储引擎完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB将它的表和索引在一个逻辑表空间中,表空间可以包含数个文件(或原始磁盘文件)。这与MyISAM表不同,比如在MyISAM表中每个表被存放在分离的文件中。InnoDB表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上
4、InnoDB支持外键完整性约束,存储表中的数据时,每张表的存储都按主键顺序存放,如果没有显示在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键
数据删除流程
InnoDB 的数据是按页存储,数据删除之后只会将原先所在的区域标记为空,这个空区域在后续插入新数据时可以被使用,同时插入数据造成 B+ 树的分裂也会造成空洞
为了消除空洞,可以使用 alter table A engine=InnoDB 命令来重建表
使用 Online DDL 之后,重建表的流程:
- 建立一个临时文件,扫描表 A 主键的所有数据页
- 用数据页中表 A 的记录生成 B+ 树,存储到临时文件中
- 生成临时文件的过程中,将所有对 A 的操作记录在一个日志文件(row log)中
- 临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 A 相同的数据文件
- 用临时文件替换表 A 的数据文件。
Buffer Pool
如何利用缓冲池将经常访问的数据保留在内存中是MySQL调优的重要方面
- 用来存放需要访问的表与索引数据
使用 LRU 算法 + 分代管理:
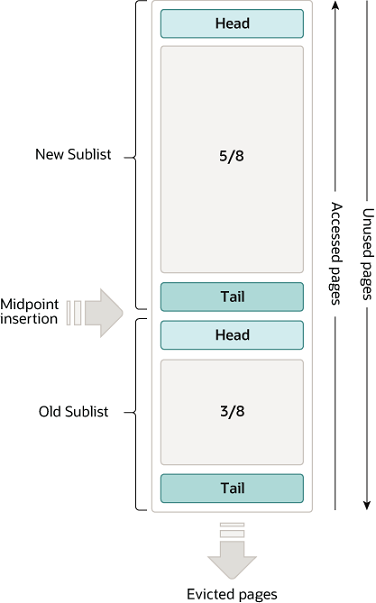
随着数据的来来往往,数据会不断老化,从队头移动到队尾
- 在进行数据扫描的过程中,需要新插入的数据页,都被放到 old 区域
- 一个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔不会超过 1 秒,因此还是会被保留在 old 区域
- 再继续扫描后续的数据,之前的这个数据页之后也不会再被访问到,于是始终没有机会移到链表头部(也就是 young 区域),很快就会被淘汰出去
这个策略最大的收益,就是在扫描这个大表的过程中,虽然也用到了 Buffer Pool,但是对 young 区域完全没有影响,从而保证了 Buffer Pool 响应正常业务的查询命中率
当出现某些情况,MySQL 会把 Buffer Pool 里的脏页flush到磁盘,这个flush操作可能会导致系统整体变慢:
- InnoDB 的 redo log 写满了。这时候系统会停止所有更新操作,把 checkpoint 往前推进,出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都必须堵住
- 当需要新的内存页,而内存不够用的时候,就要淘汰一些数据页,空出内存给别的数据页使用,如果淘汰的有脏页,就需要flush,一个查询要淘汰的脏页个数太多,会导致查询的响应时间明显变长
- 系统空闲期自动flush
- 系统关闭时flush
flush 的策略:
- 要通过innodb_io_capacity参数告诉 InnoDB 所在主机的 IO 能力,这个数值可以设置成fio测试得到的IOPS
- 脏页比例越大或者日志没有被flush的长度越大,刷脏页速度也就越大
- 在准备刷一个脏页的时候,如果这个数据页旁边的数据页刚好是脏页,就会把这个“邻居”也带着一起刷掉,而且邻居的邻居也会继续被带上,innodb_flush_neighbors 参数就是用来控制不找邻居,自己刷自己。找“邻居”这个优化在机械硬盘时代是很有意义的,可以减少很多随机 IO
Change Buffer
因为二级索引不像聚簇索引,不唯一、插入随机,所以划分一块单独的内存区域,用来缓存二级索引页面
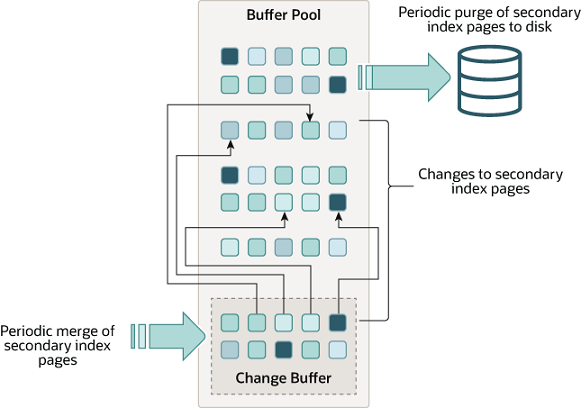
当需要更新一个数据页时,如果数据页在内存中就直接更新,如果不在内存中,在不影响数据一致性的情况下,会将更新的操作缓存在 Change Buffer 里面,当读取这些受影响的数据时,会执行 merge 操作,对数据应用这些操作,同时 MySQL 也会定期将这些更新转为对物理数据的真正更新
Change Buffer 会被持久化到磁盘中,事务提交的时候,Change Buffer 的操作也会被记录到 redo log 里
这个缓冲,对于写多读少的业务效果最好,如果读的比较多,每次读取都要触发 merge 操作,也就是从磁盘再去读数据
MEMORY存储引擎
1、MEMORY表的每个表可以有多达32个索引,每个索引16列,以及500字节的最大键长度
2、MEMORY存储引擎执行HASH和BTREE缩影
3、可以在一个MEMORY表中有非唯一键值
4、MEMORY表使用一个固定的记录长度格式
5、MEMORY不支持BLOB或TEXT列
6、MEMORY支持AUTO_INCREMENT列和对可包含NULL值的列的索引
7、MEMORY表在所由客户端之间共享(就像其他任何非TEMPORARY表)
8、MEMORY表内存被存储在内存中,内存是MEMORY表和服务器在查询处理时的空闲中,创建的内部表共享
9、当不再需要MEMORY表的内容时,要释放被MEMORY表使用的内存,应该执行DELETE FROM或TRUNCATE TABLE,或者删除整个表(使用DROP TABLE)
对比
| 功能 | MYISAM | Memory | InnoDB | Archive |
|---|---|---|---|---|
| 存储限制 | 256TB | RAM | 64TB | None |
| 支持事务 | No | No | Yes | No |
| 支持全文索引 | Yes | No | Yes(5.6之后) | No |
| 支持数索引 | Yes | Yes | Yes | No |
| 支持哈希索引 | No | Yes | No | No |
| 支持数据缓存 | No | N/A | Yes | No |
| 支持外键 | No | No | Yes | No |
如何选择合适的存储引擎
根据引擎特性:
大多数时候我们使用的都是 InnoDB 存储引擎,但是在某些情况下使用 MyISAM 也是合适的比如读密集的情况下,或者比如只有MyISAM支持地理空间搜索
除非万不得已 否则不要混用引擎。
根据应用特性:
电商网站必须支持事务,肯定得用InnoDB,BBS类型的网站经常统计COUNT,MyISAM可能会比较快。
引擎转换
- ALTER TABLE
- 这种方式是通过将数据从原表复制到新表中
- mysqldump导出数据
- INSERT ... SELECT 语法