大数据
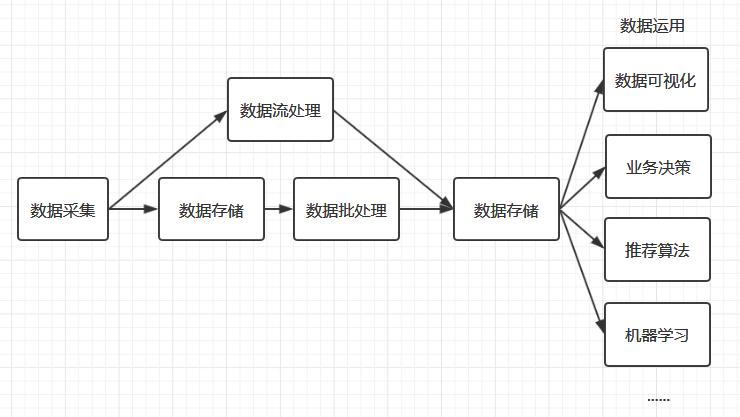
- 数据采集:Flume 、Logstash、Kibana 等
- 数据存储: HBase
- 批处理:Hadoop MapReduce、Spark、Flink
- 流处理:Storm、Spark Streaming、Flink Streaming
计算向存储移动
- 大规模数据存储在服务器集群的所有服务器上
- 分布式启动若干任务执行进程
- 分布式计算编程模型:MapReduce、RDD等,上传代码到各台服务器上
- 服务器执行代码,代码读取数据进行分布式计算与合并结果
特点
4V:
- Volume 大量
- Velocity 高速
- Variety 多样
- Value 低价值密度
大数据生态体系
大数据生态演化
stateDiagram-v2
起源 --> OLAP计算MapReduce
OLAP计算MapReduce --> 太慢
太慢 --> 流式计算
流式计算 --> S4/Storm
S4/Storm --> 至少一次消息模型计算不准确
至少一次消息模型计算不准确 --> Lambda架构
Lambda架构 --> MapReduce+Spark
MapReduce+Spark --> 维护两套架构麻烦
维护两套架构麻烦 --> 正好一次消息模型
正好一次消息模型 --> Kappa架构,KafkaStream
Kappa架构,KafkaStream --> DataFlow模型,Flink
起源 --> OLTP服务BigTable
OLAP计算MapReduce --> 编程麻烦
OLAP计算MapReduce --> 数据缺少Schema
OLAP计算MapReduce --> 单轮计算过多的硬盘读写
编程麻烦 --> 引入类SQL与Schema
数据缺少Schema --> 引入类SQL与Schema
引入类SQL与Schema --> Hive
单轮计算过多的硬盘读写 --> Spark
Hive --> 等待结果过久
等待结果过久 --> 使用服务树架构,中间计算节点常驻
使用服务树架构,中间计算节点常驻 --> Dremel
OLTP服务BigTable --> 缺少Schema,没有跨行事务
缺少Schema,没有跨行事务 --> 引入类SQL与Schema+引入EntityGroup
引入类SQL与Schema+引入EntityGroup --> Megastore
Megastore --> 写入吞吐量不足,跨行事务限于EntityGroup内
写入吞吐量不足,跨行事务限于EntityGroup内 --> Spanner
Hive
它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,但受限于编程模型,一些诸如嵌套SQL等标准SQL的功能是不支持的
- 离线分析
Hive 通过一些中间层,数据行与HDFS之间可以进行转换:
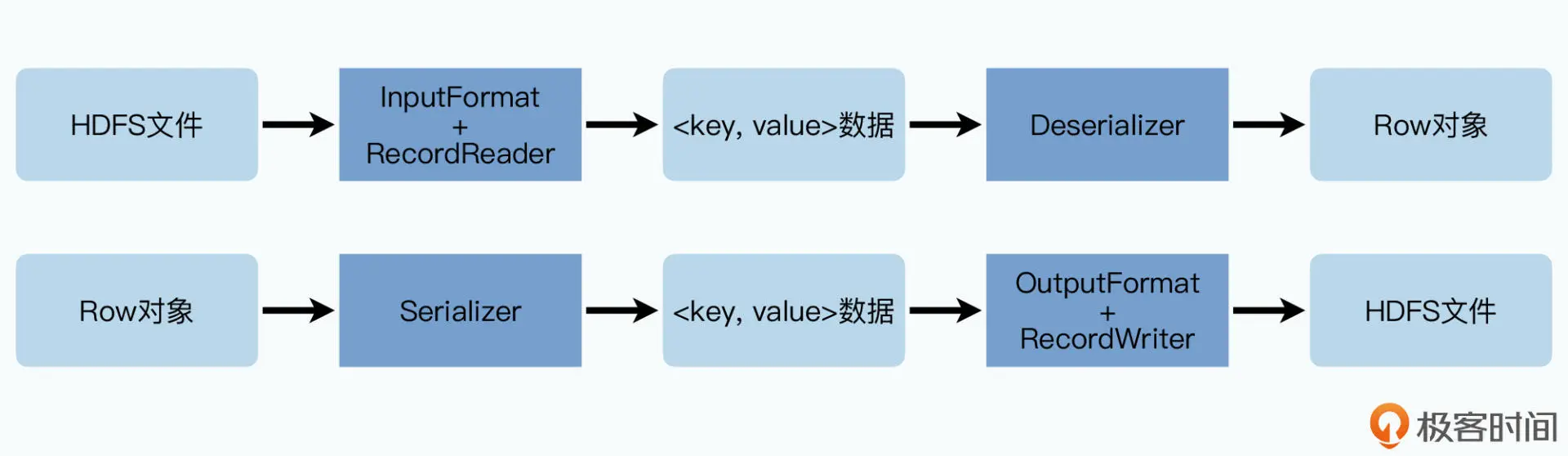
Hive 通过数据分区的方式来避免在进行 SQL 查询的全表扫描,而且还能再根据列的哈希值,进一步分桶
整体架构:
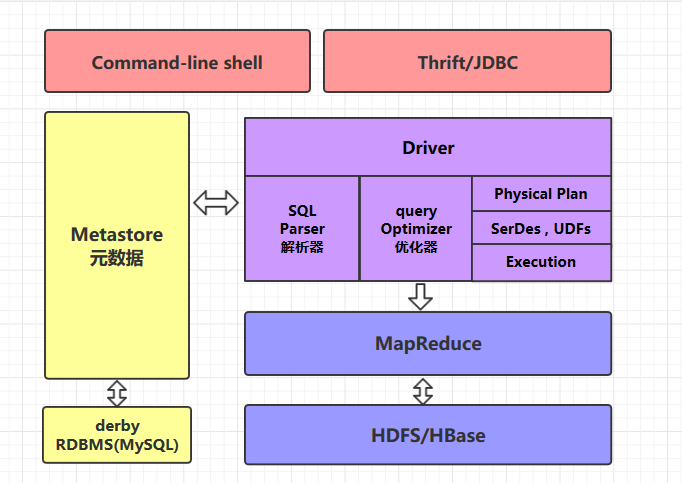
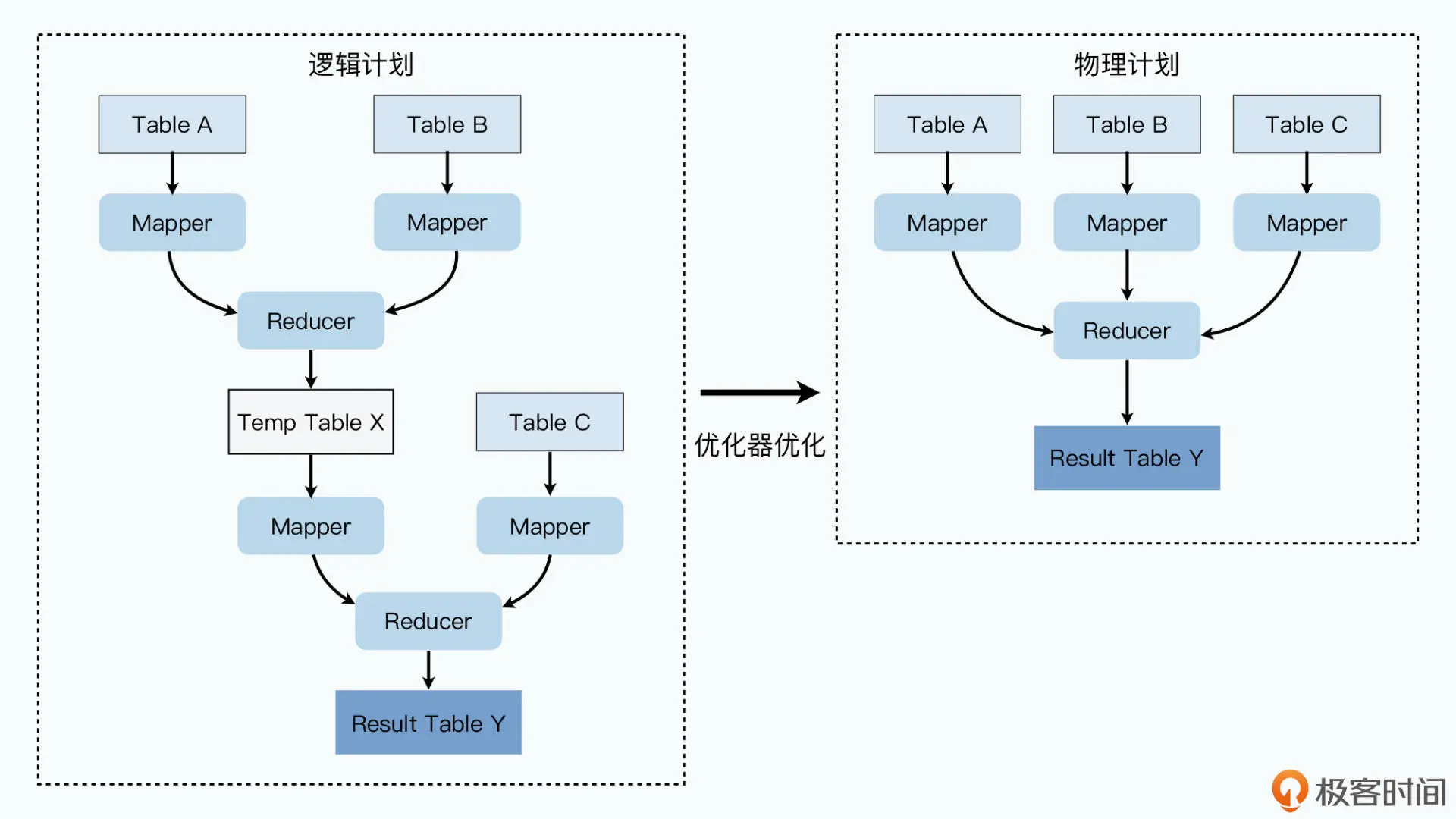
编译器会把 HQL 编译成一个逻辑计划(Logical Plan),SELECT 里的字段需要通过 map 操作获取,也就是需要扫描表的数据。Group By 的语句需要通过 reduce 来做分组化简,而 Join 则需要两个前面操作的结果的合并
优化器会在必要时比如发现 JOIN 的 key 都是相同时对 MapReduce 进行优化:
SELECT A.user_id, MAX(B.user_interests_score), SUM(C.user_payments)
FROM A
LEFT JOIN B on A.user_id = B.user_id
LEFT JOIN C on A.user_id = C.user_id
GROUP BY A.user_id
Hive 的所有数据表的位置、结构、分区等信息都在 Metastore 里,通常是使用中心化的关系数据库来进行存储
Hbase
- 构建在 Hadoop 文件系统之上的面向列的数据库管理系统
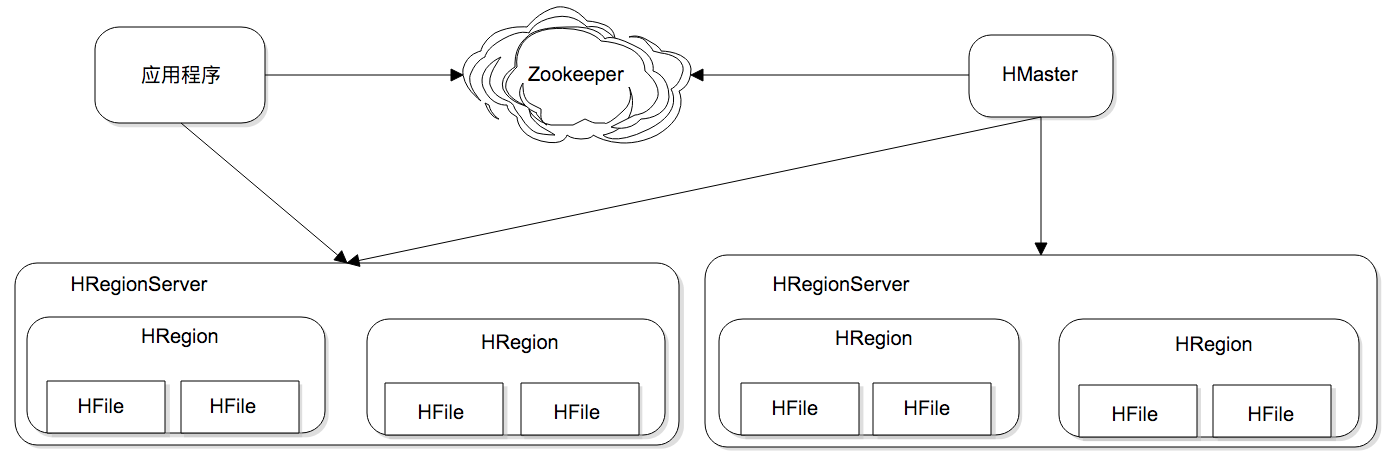
HRegion 是负责数据存储的主要进程,每个 HRegionServer 上可以启动多个 HRegion 实例,当一个 HRegion 中写入的数据太多,一个 HRegion 会分裂成两个,进行负载迁移
sequenceDiagram
应用程序 ->> ZK: 请求HMaster地址
应用程序 ->> HMaster: 输入key,请求HRegionServer地址
应用程序 ->> HRegionServer: 输入key,查询数据
HRegionServer ->> HRegion: 访问实例获取数据
Phoenix:HBase 的开源 SQL 中间层
BigTable
基本数据模型:
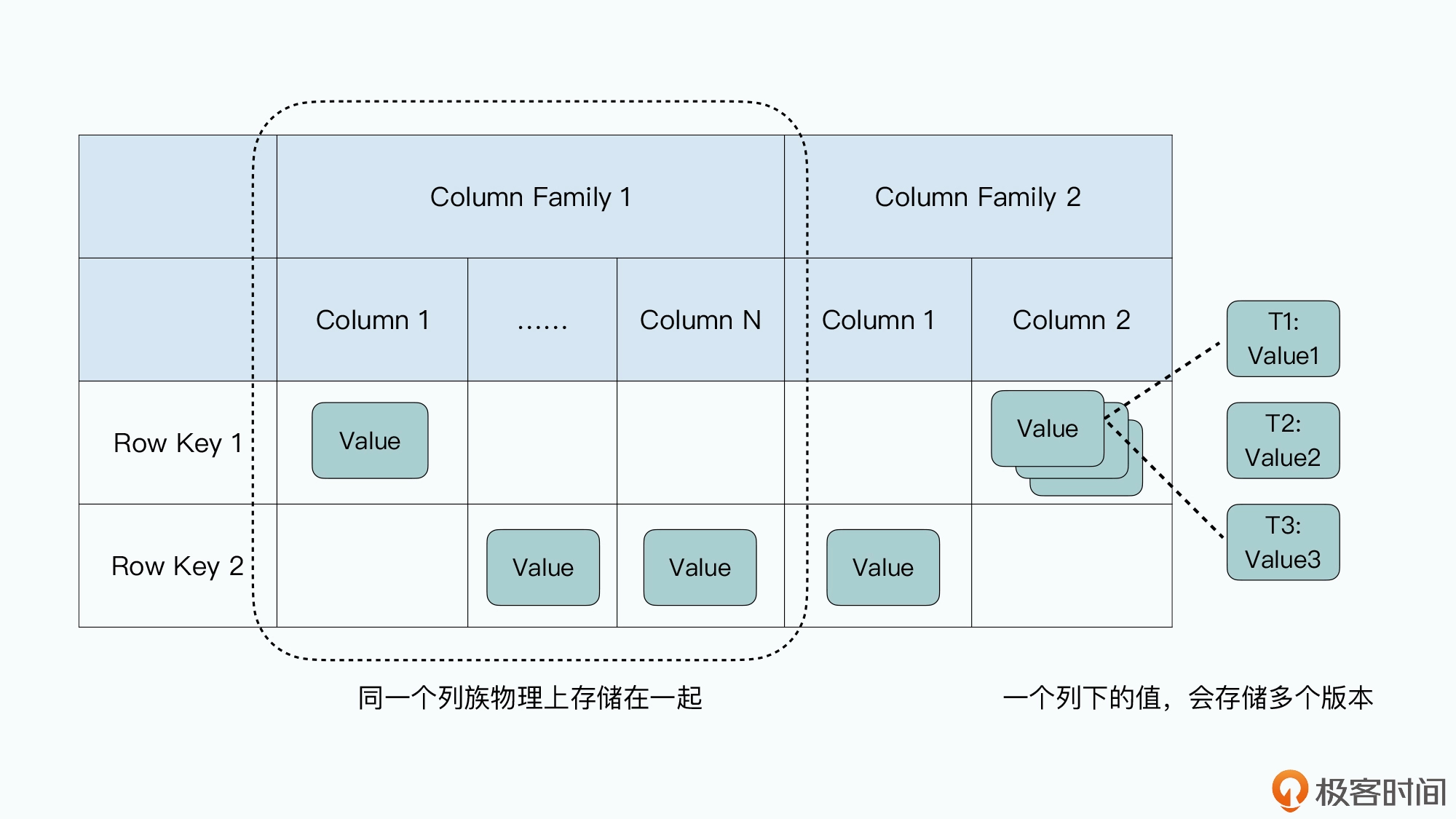
- 一条数据里面有一个行键(Row Key),也就是这条数据的主键
- 每一行里的数据需要指定一些列族(Column Family),每一条数据都可以有属于自己的列,每一行数据的列也可以完全不一样
- 列下面如果有值的话,可以存储多个版本,不同版本都会存上对应版本的时间戳(Timestamp),你可以指定保留最近的 N 个版本
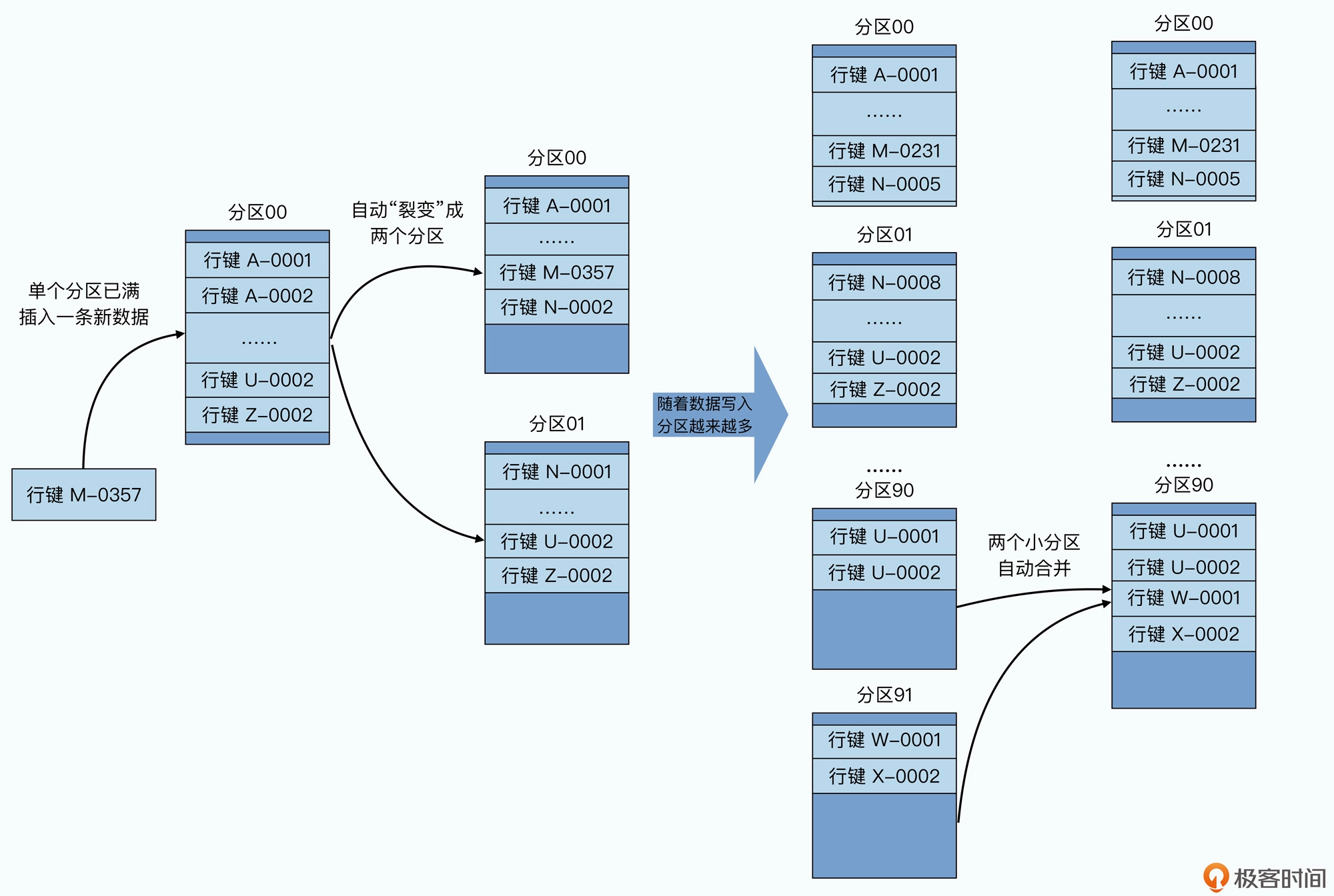
数据分区:
采用了动态区间分区的方式,按照行键排好序,然后按照连续的行键一段段地分区,随着数据的大小自动进行分裂或者合并
- Tablet Server:实际提供数据读写服务的,会分配到 10 到 1000 个 Tablets(分区),Tablet Server 就去负责这些 Tablets 的读写请求,并且在单个 Tablet 太大的时候,对它们进行分裂
- Master:负责分区分配、对每个 Tablet Server 进行负载调度、检测 Tablet Server 的新增和过期、对于 GFS 上的数据进行GC、管理表(Table)和列族的 Schema 变更
- Chubby:Master 选主、存储 Bigtable 数据的引导位置、发现 Tablet Servers 以及在它们终止之后完成清理工作、存储 Schema 信息、存储 ACL 访问权限
数据读写:
分区和 Tablets 的分配信息存放在了 Bigtable 的一张 METADATA 表,通过 Chubby 的引导,客户端可以实现不经过 Master 就能读取这些元数据
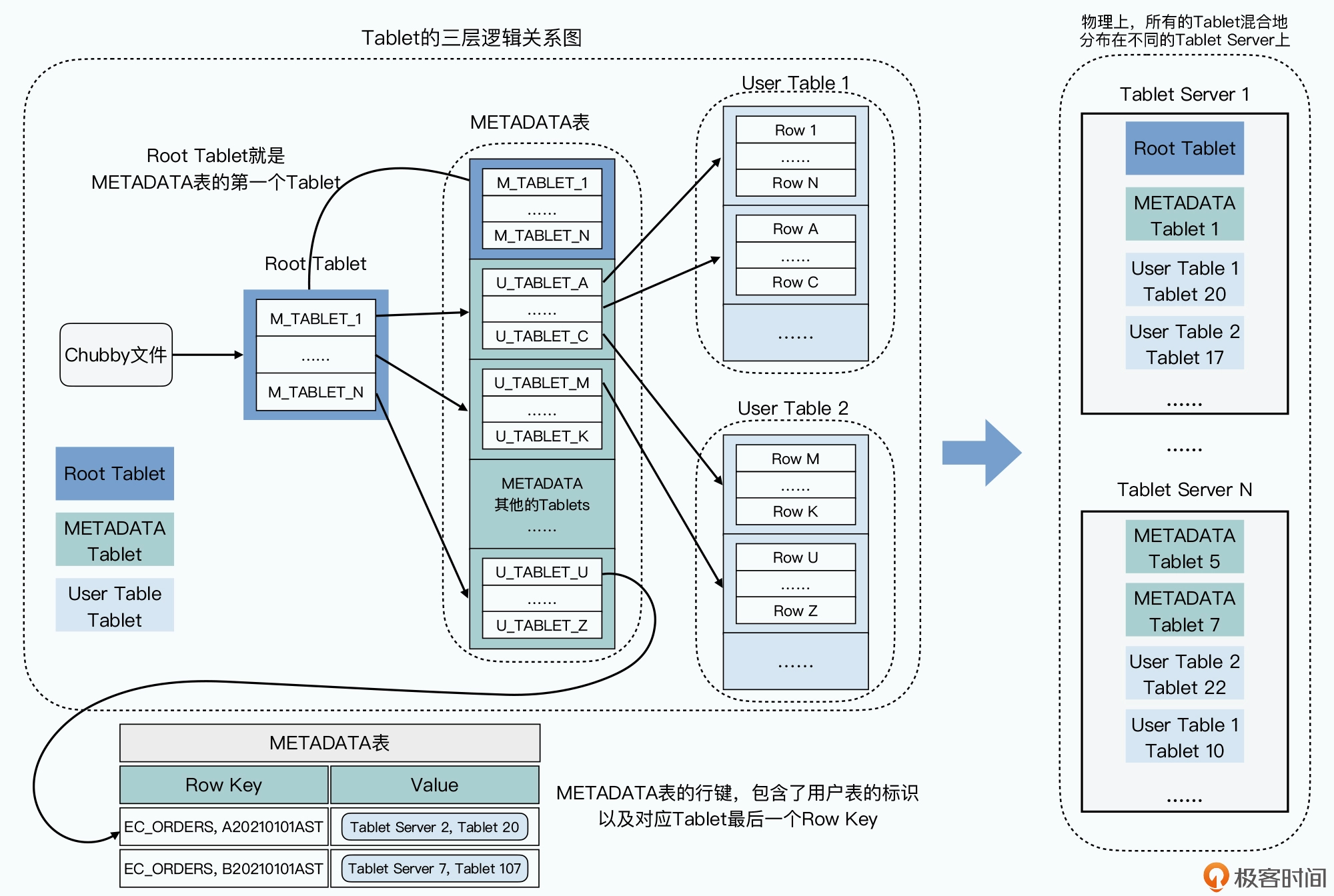
sequenceDiagram
客户端 ->> Chubby: 查询 Root Tablet
Chubby ->> 客户端: 返回 RootTablet 所在的 TabletServerX
客户端 ->> TabletServerX: 查询所需要的表在哪个 METADATA Tablet
TabletServerX ->> 客户端: 返回 METADATA Tablet 所在的 TabletServerY
客户端 ->> TabletServerY: 查询所需要的表在哪个 TabletServer
TabletServerY ->> 客户端: 返回数据所在的 TabletServerZ 和 Tablet 编号
客户端 ->> TabletServerZ: 查询所需要的数据
TabletServerZ ->> 客户端: 返回数据
用了三次网络查询,找到了想要查询的数据的具体位置,然后再发起一次请求拿到最终的实际数据,一般会把前三次查询位置结果缓存起来,以减少往返的网络查询次数。而对于整个 METADATA 表来说,会把它们保留在内存里,减少对 GFS 的访问
查询 Tablets 在哪里这件事情,尽可能地被分摊到了 Bigtable 的整个集群,即使 Master 挂掉了,也不影响读写
调度:
Master 通过监听 Chubby 的目录,TabletServer 上线会向这个目录注册,这样就能发现有没有新的 TabletServer 可以用了,TabletServer 通过对锁的独占来确定自己是否还为自己分配到的 Tablets 服务,如果 TabletServer 下线了,这些 Tablets 都需要重新分配,Master 如果发现 TabletServer 下线了,则会自己去尝试获取一下这个锁,如果获取得到,一切正常,就对 TabletServer 进行清退,如果 Master 发现自己跟 Chubby 连接有问题,就选择自杀,以避免脑裂
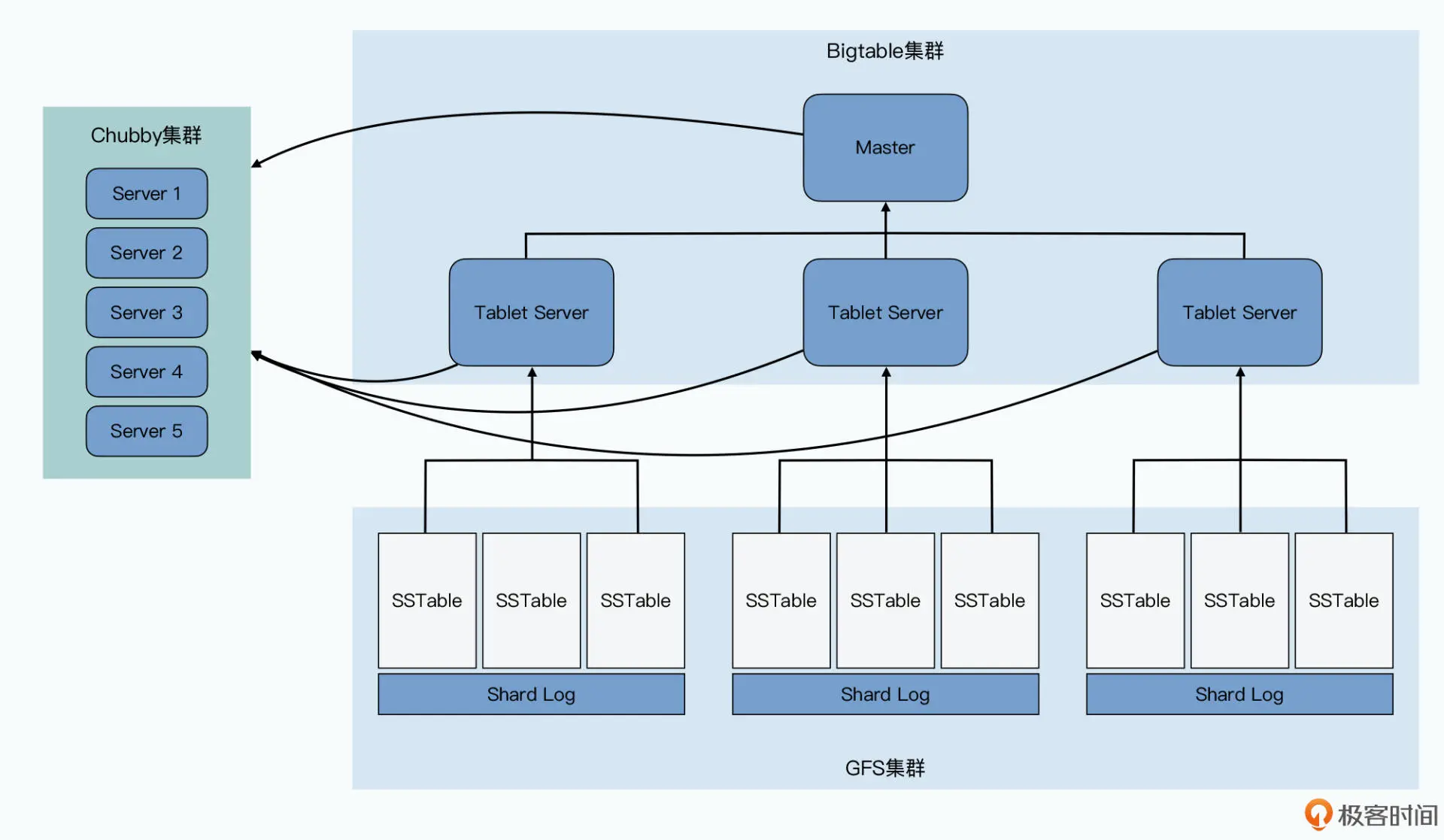
Bigtable 为了在不可靠跟全是机械硬盘的 GFS 上面做到高性能的随机读写,没有在 GFS 上进行任何的随机写入,这是通过 LSM树来实现通过顺序的写实现随机的写
由于 LSM树查询需要遍历所有的 SSTable直至找到所需要的key,为了提升查询效率, BigTable 有几个手段:
- 定期在后台合并 SSTable,以减少读请求需要访问的 SSTable 的数量
- 通过在内存里缓存 BloomFilter 过滤掉不存在于 SSTable 中的 key
- 通过 Scan Cache 和 Block Cache 两层缓存,利用局部性原理,使得查询结果可以在缓存中找到
- Scan Cache:针对某个 key 的结果的缓存
- Block Cache:查询某个 key ,与该 key 在同一个数据块的全部数据缓存
Megastore
Megastore 是直接在多个数据中心里,采用 Paxos 同步写入数据,是一个同步复制所有的数据库日志,但是没有主从区分的系统
实际应用层面,对于“可串行化”以及“可线性化”的需求并不是全局的,而是可以分区的,分区内的事务是可以保证的
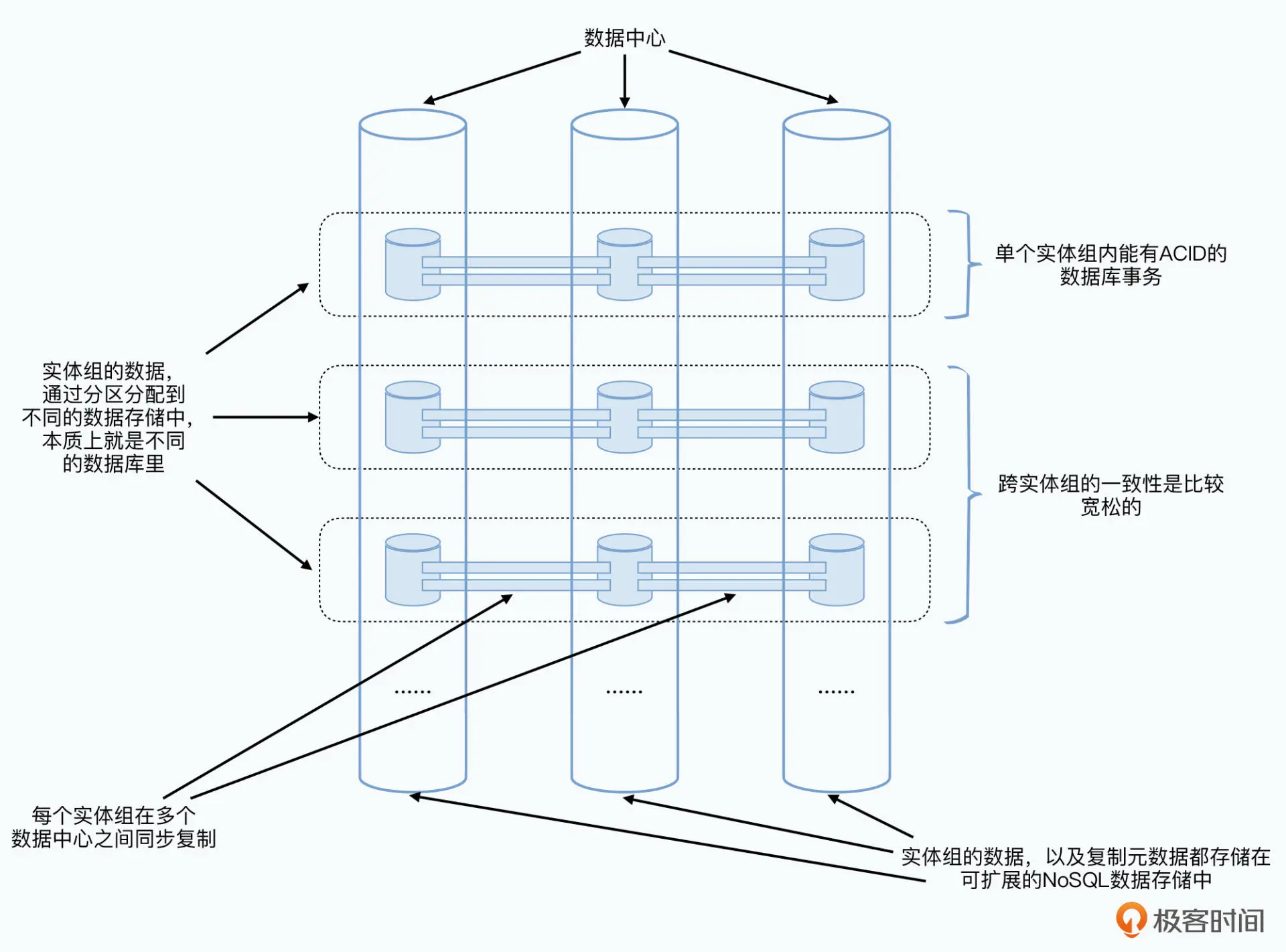
分区之间通过数据同步来达到最终一致性,也可以通过重量级的两阶段提交来实现事务
索引机制:
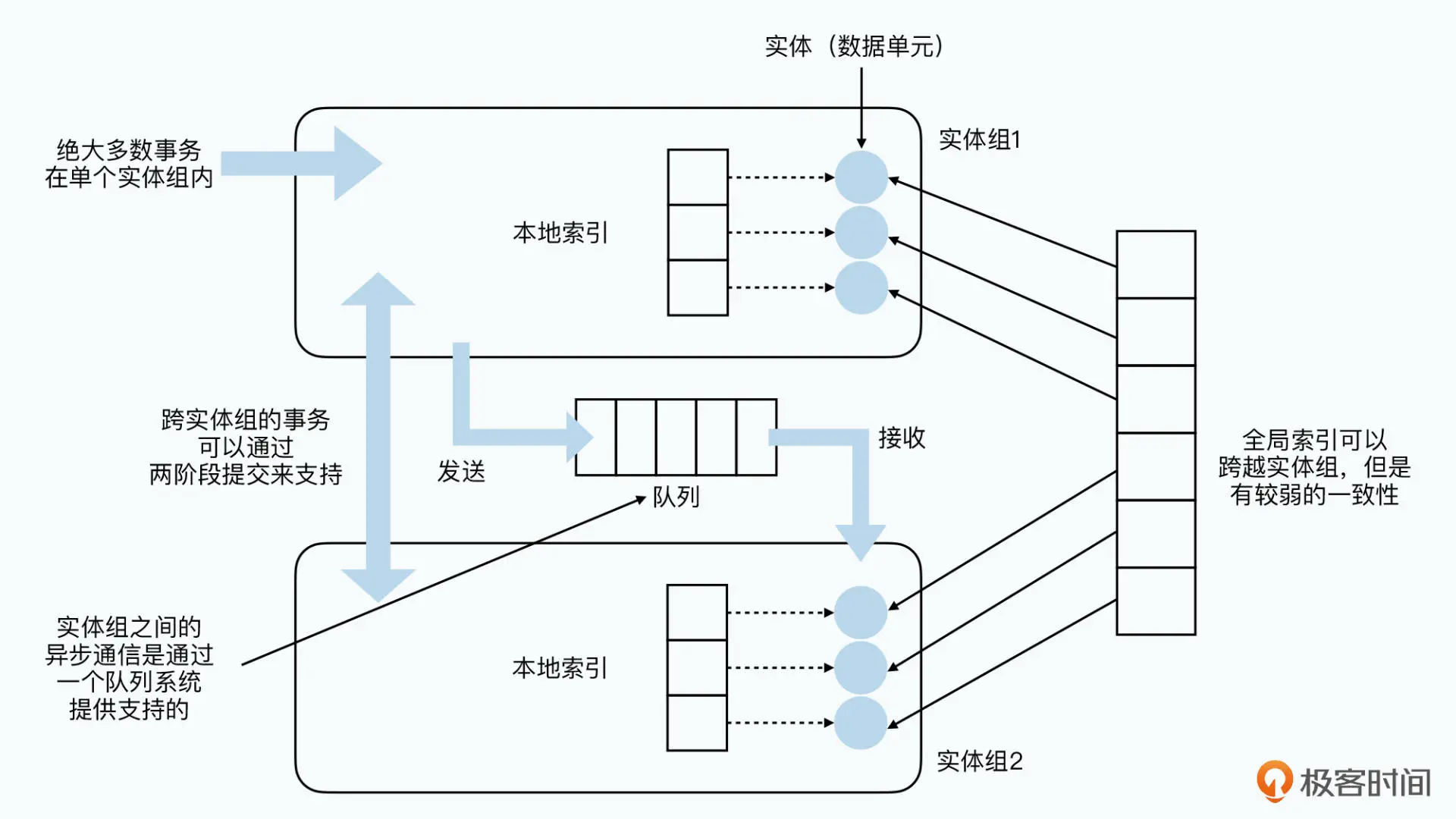
- Megastore 可以通过一个 STORING 语句,指定索引里存储下对应的数据记录的某一个字段的值,这样就不会回表查询,相比单体数据库不仅少了磁盘读,还少了一次网络往返
- 可以为 repeated 类型的字段建立索引(Repeated Indexes)
- 内联索引(Inline Indexes)的支持
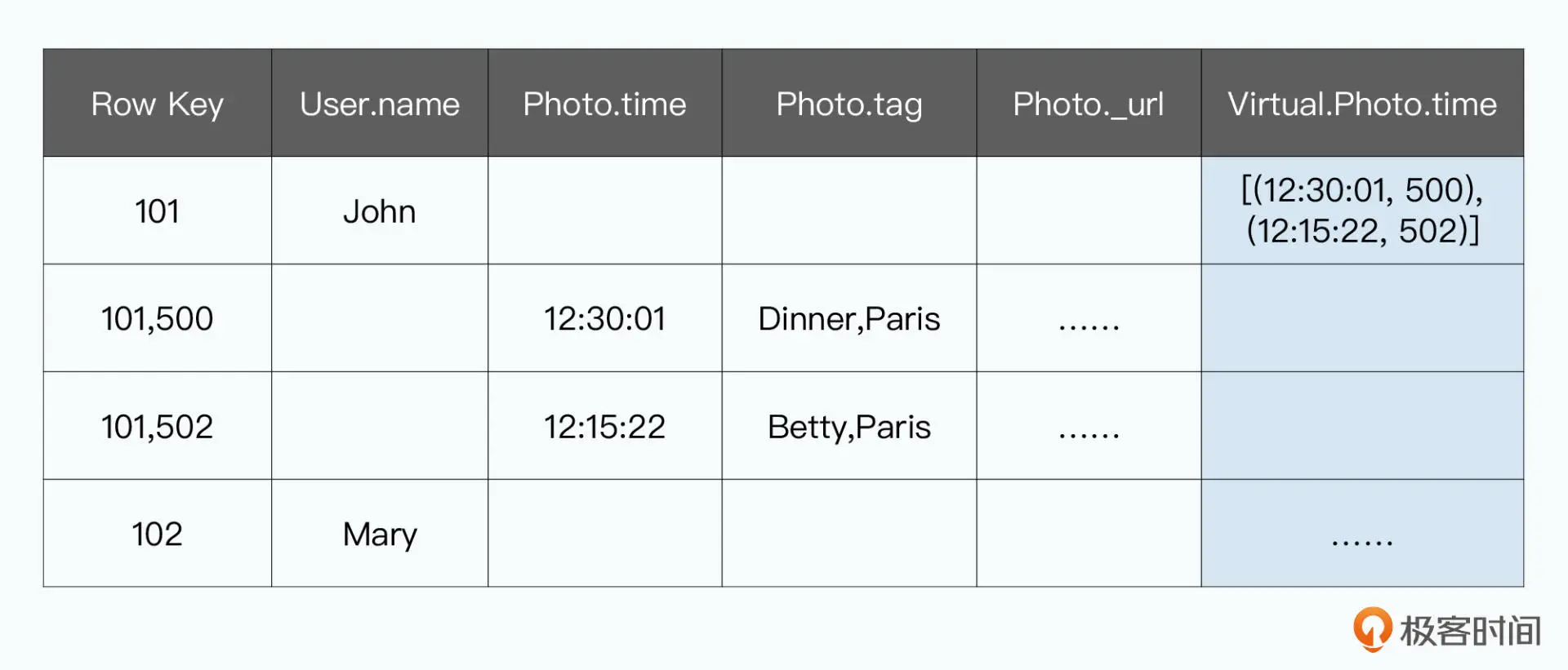
索引的实现,也是BigTable中的一条条记录:
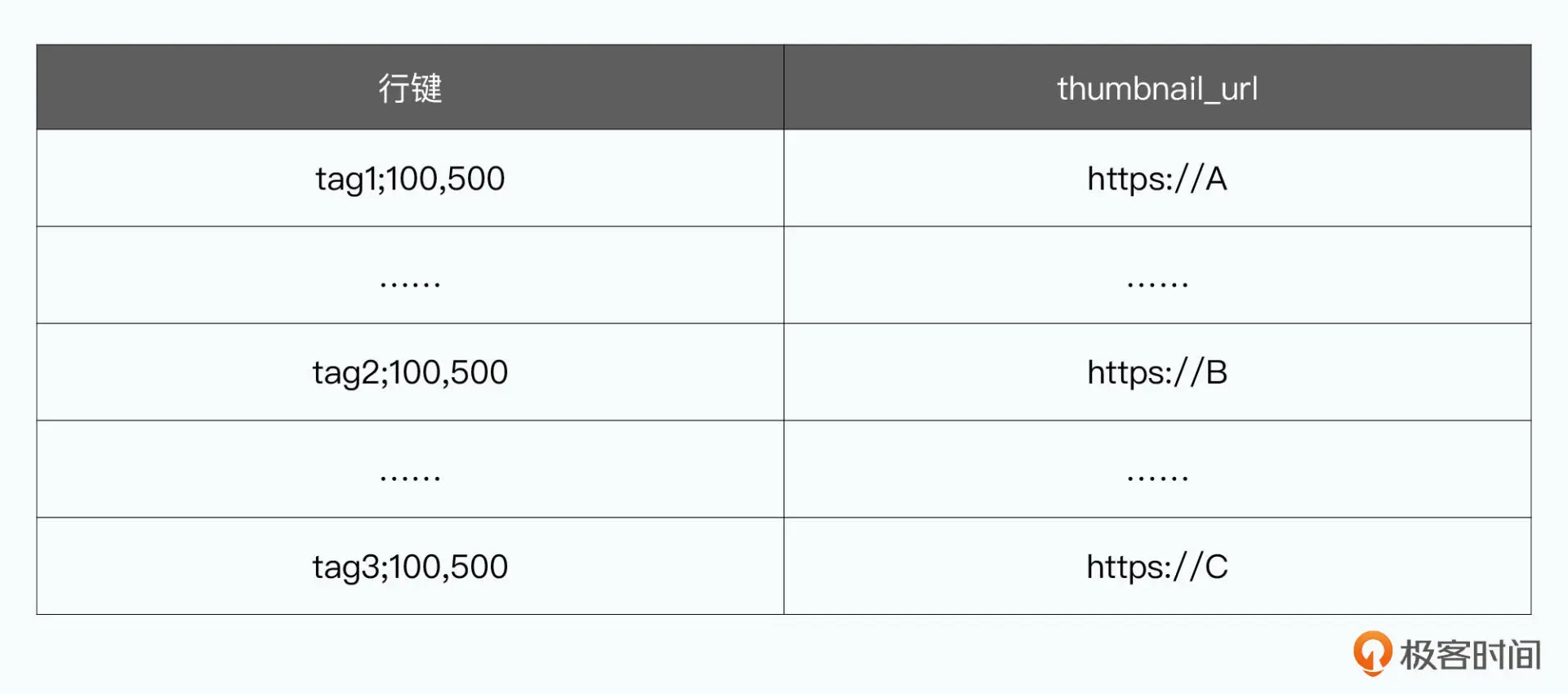
事务:
Megastore 利用 BigTable 会维护多版本数据的特性,使用时间戳作为版本号,实现了 MVCC
- 读(Read):我们先要获取到时间戳,以及最后一次提交的事务的日志的位置
- 应用层的逻辑(Application Logic):我们要从 Bigtable 读取数据,并且把所有需要的写操作,收集到一条日志记录(log entry)中
- 提交事务(Commit):通过 Paxos 算法,我们要和其他数据中心对应的副本,达成一致,把这个日志记录追加到日志的最后
- 应用事务(Apply):也就是把实际对于实体和索引的修改,写入到 Bigtable 里
- 清理工作(Clean UP):也就是把不需要的数据删除掉。
确保数据的可线性化:
- 每一次读都需要能够观察到最后一次被确认的写入
- 一旦一个写入被观察到了,所有未来的读取都能观察到这个写入
为了能快速且一致地读取数据,快速读:
- 查询本地的协同服务器,协同服务器用来追踪一个当前数据中心的副本里,已经观察到的最新的实体组的集合,类似于 Kafka 的 ISR
- 根据查询的结果,来判断是从本地副本还是其他数据中心的副本,找到最新的事务日志位置,这个日志位置就是一个编号,由于这个编号是存在 BigTable 里面的
- 根据协同服务器的结果,判断本地副本是不是最新的,如果不是,本地副本就要进行一个追赶共识,也就是通过 Paxos 去达成数据的一致性
- 然后就可以查询数据了
sequenceDiagram
客户端 ->> 协作服务器: 获取最新实体组集合
客户端 ->> 本地副本A: 查询最新事务日志编号
opt 如果本地副本不是最新,发起多数投票读取
客户端 -->> 远端副本A:
客户端 -->> 远端副本B:
end
opt 发起多数投票读取后,本地追赶远端
本地副本A ->> 远端副本A:
本地副本A ->> 远端副本B:
客户端 ->> 协作服务器: 数据已经最新
end
客户端 ->> 本地副本A: 查询数据
本地副本A ->> 客户端: 返回数据
快速写:
写入数据之前,客户端会先“读”一次数据,确保能够拿到下一次事务日志位置、最后一次写入数据的时间戳,以及哪一个副本在上次一次 Paxos 算法的时候,被确定是整个集群的 Leader
- Accept Leader 阶段:直接向 Leader 副本发起一个 Accept 请求,如果被接受了,则跳到第3步
- 如果第 1 步失败了,正常走一个 Paxos 算法的流程,向所有的副本,发起一个 Prepare 请求,编号是当前客户端的最大编号 + 1
- Accept 阶段:所有副本都去接收客户端发起的提案
- 向所有没有 Accept 最新的值的副本,发起一个 Invalidate 的请求
- Apply 阶段:客户端会让尽可能多的副本,去把实际修改应用到数据库里
Megastore 对于每一个数据中心的副本有三种类型:
- 完全副本
- 见证者副本:只参与投票,并且记录事务日志。但是它不会保留实际的数据库数据
- 只读副本:异步复制的数据副本
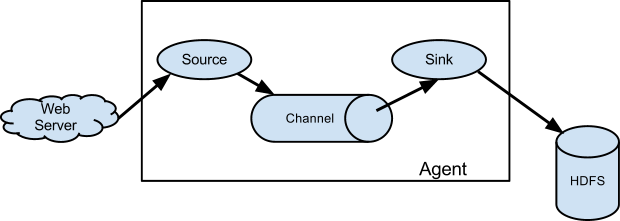
Flume
- 数据收集系统,通常用于日志数据的收集
Spanner
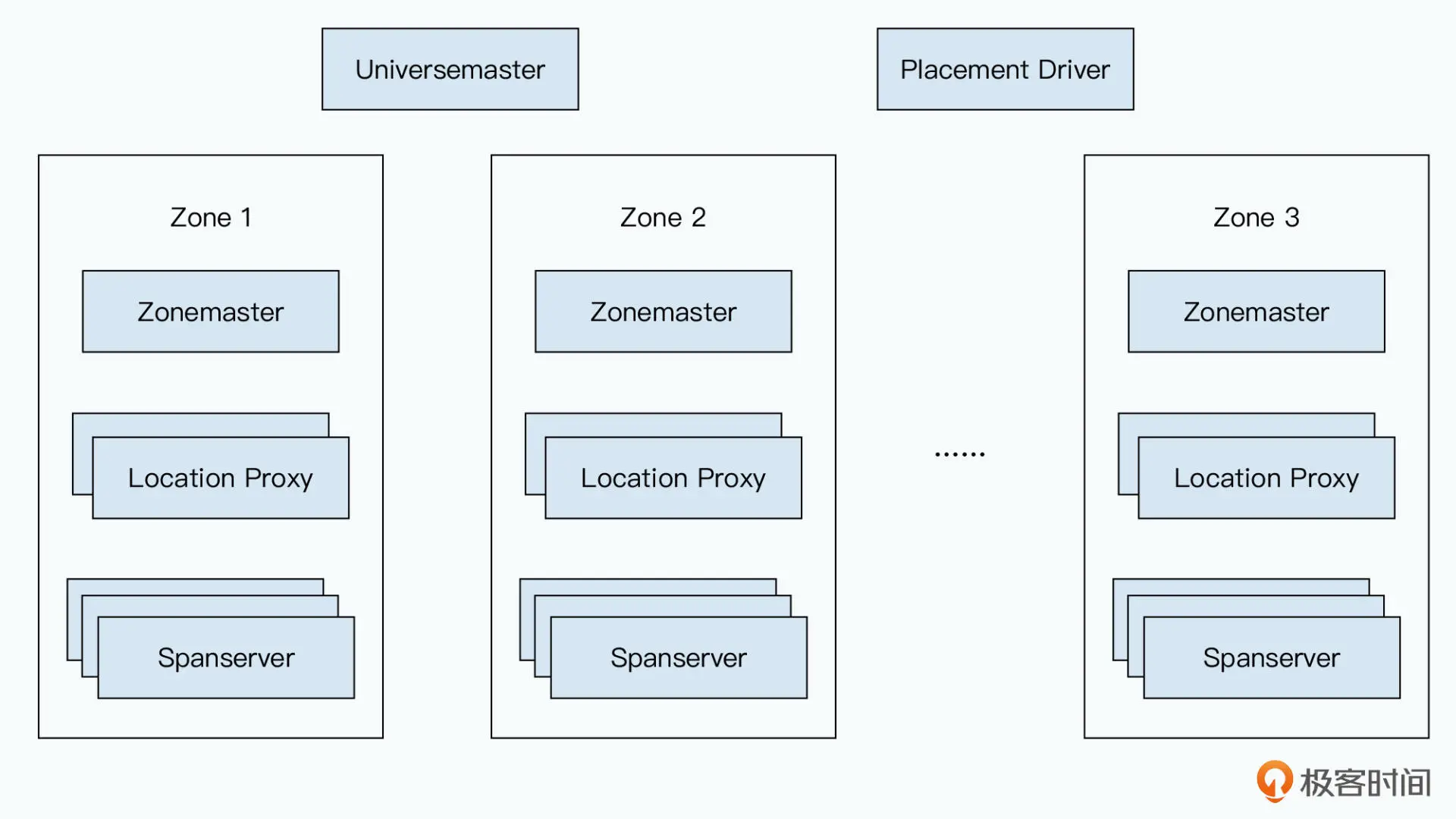
- Universemaster:提供一系列的控制台信息,主要是 Zone 的各种状态信息
- Placement Driver:负责调度数据到不同的 Zone 里面
- Zonemaster: 负责将数据分片分配给不同的 Spanserver
- Spanserver:负责管理一部分数据的存储并向客户端提供服务
- Location Proxy:在客户端和 Spanserver 之间的代理服务器,客户端在请求数据时先访问 Location Proxy,Location Proxy 会告诉客户端需要访问哪个 Spanserver 来获取所需的数据
Spanserver
Spanner 的底层数据存储,是一个 B 树数据结构,以及对应的预写日志(WAL)
为了保障数据的同步复制,Spanserver 通过 Paxos 算法。数据写入,都是从 Leader 发起的,但是所有的其他副本,也都会拥有完整的数据,Spanner 会写入两份日志,一份是 Paxos 日志,一份是 Tablet 日志
每个 Paxos 组包含一个 Tablet 和其所有副本,一个 Paxos 组可以包含多个目录,可以将那些频繁共同访问的目录调度到相同的 Paxos 组中,从而提高读写性能。数据在不同 Paxos 组之间的转移,则是通过一个 movedir 的后台任务,先在后台转移数据,而当所有数据快要转移完的时候,再启动一个事务转移最后剩下的数据,来减少可能的阻塞时间
每个 Spanserver 上,会有一个事务管理器,用来支持分布式事务。这个事务管理器,就是一个参与者 Leader(Participant Leader),这个参与者 Leader 会和其他的参与者 Leader 协商,来完成事务的两阶段提交
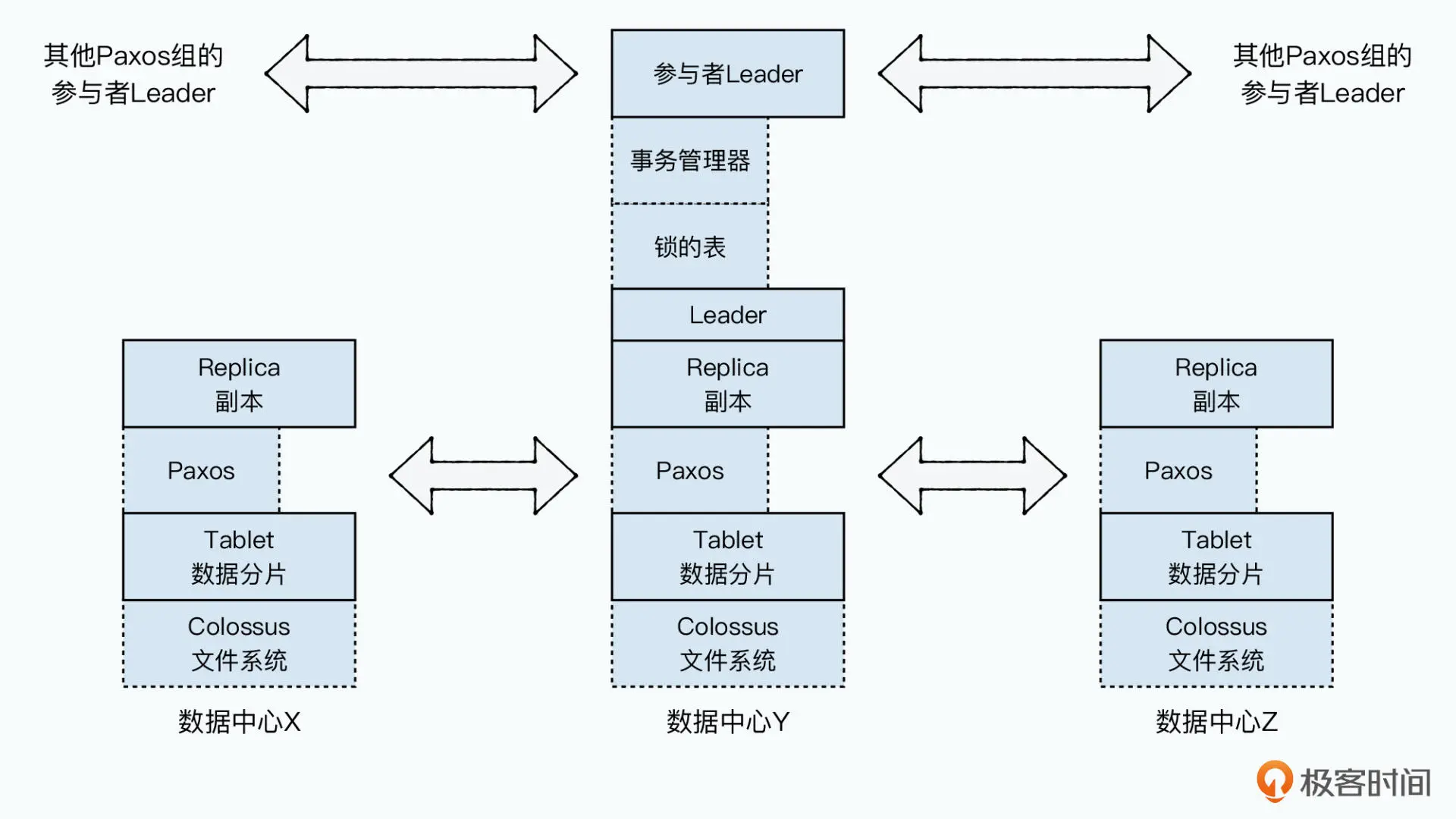
通过缩小时间戳误差,通过原子钟 + GPS,还有时间置信区间,只要保证晚提交的事务的时间戳,一定比早提交事务的时间戳晚,那就可以确保事务的可线性化
可线性化是一个分布式系统中的概念。它的含义是,对单个对象上的操作,是“实时”的。也就是你对一个数据写入操作成功了,那么立刻去读取它,就会读到刚刚写入的值
同时保障可串行化和可线性化称之为严格串行化
S4
S4 把所有的计算过程,都变成了一个个处理元素(Processing Element)对象,简称为 PE 对象,每一个 PE 对象,都有四部分要素组成:功能、能够处理的事件类型、能处理的事件的键值,流式的数据处理,就是由一个个 PE 组成的有向无环图(DAG)
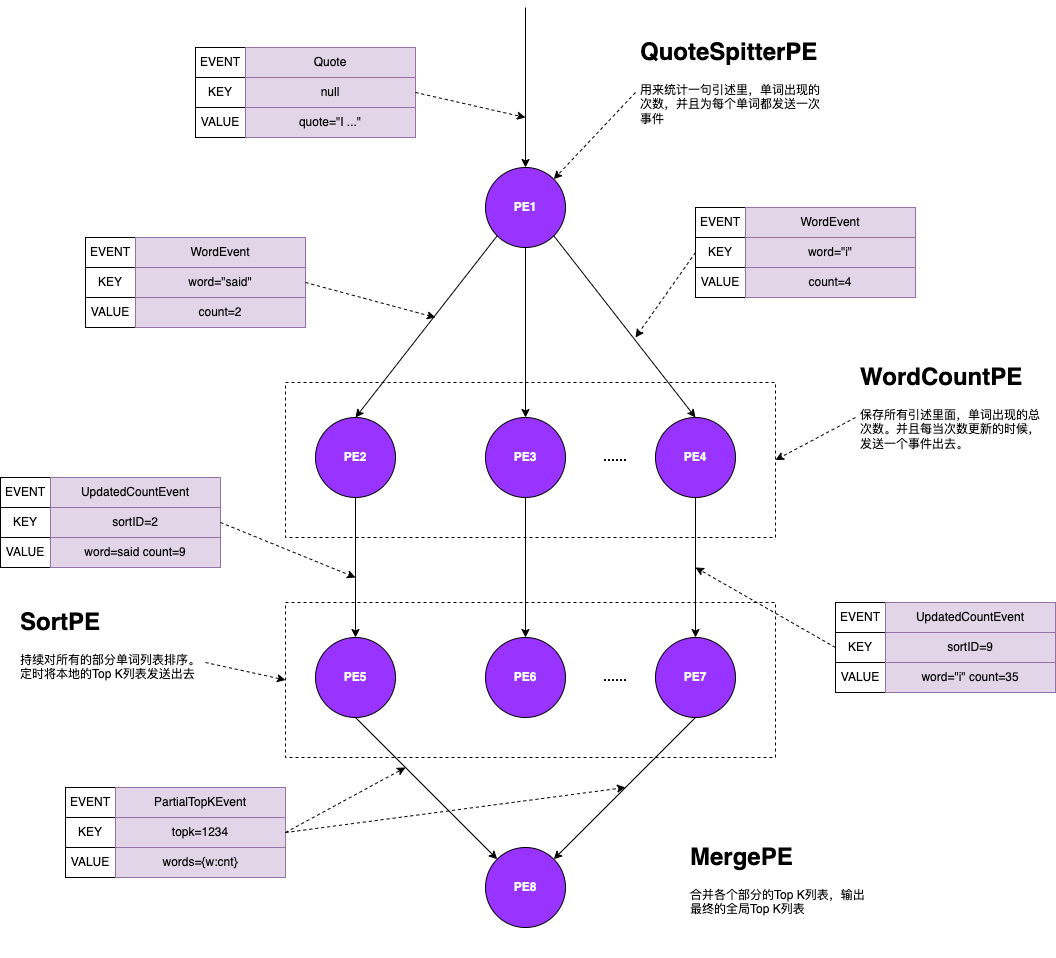
S4 依赖于 Zookeeper,S4 的所有服务器,都会作为一个处理节点(ProcessingNode),简称 PN 注册在 Zookeeper 上。具体如何分配负载,是由各个节点协商决定的,由于没有中心节点,虽然规避了单点故障,但是也因此放弃了动态扩容,而且也没法处理节点故障,数据丢失的问题
Storm
Storm 的有向无环图叫做 Topology
stateDiagram
direction LR
spout --> blot1
blot1 --> blot2
blot1 --> blot3
- Spouts,也就是数据源,负责从外部去读取数据或者接收数据
- Tuple,传输的所有的最小粒度的数据单元
- Streams,也就是数据流,一个流包含了无限多个 Tuple 的序列,这些 Tuple 会被系统分布式地并行去处理
- Bolts,也就进行计算逻辑处理的地方
Storm 是一个典型的 Master+Worker 的分布式系统架构,它由 Nimbus+Supervisor+Worker 三种类型进程构成
- Nimbus 进程,负责资源的分配和任务的调度
- Supervisor 进程,负责接收 Nimbus 分配的任务,然后管理本地的 Worker 进程,让 Worker 进程来实际执行任务
- Worker 进程,每一个 Worker 进程就是一个独立的 JVM,Worker 里面还会通过 JVM 的 Executor 来维护一个线程池。然后实际的线程池里,会有很多个 Spout/Bolt 的任务
Flink
- 分布式的流处理框架,它能够对有界和无界的数据流进行高效的处理
大数据平台
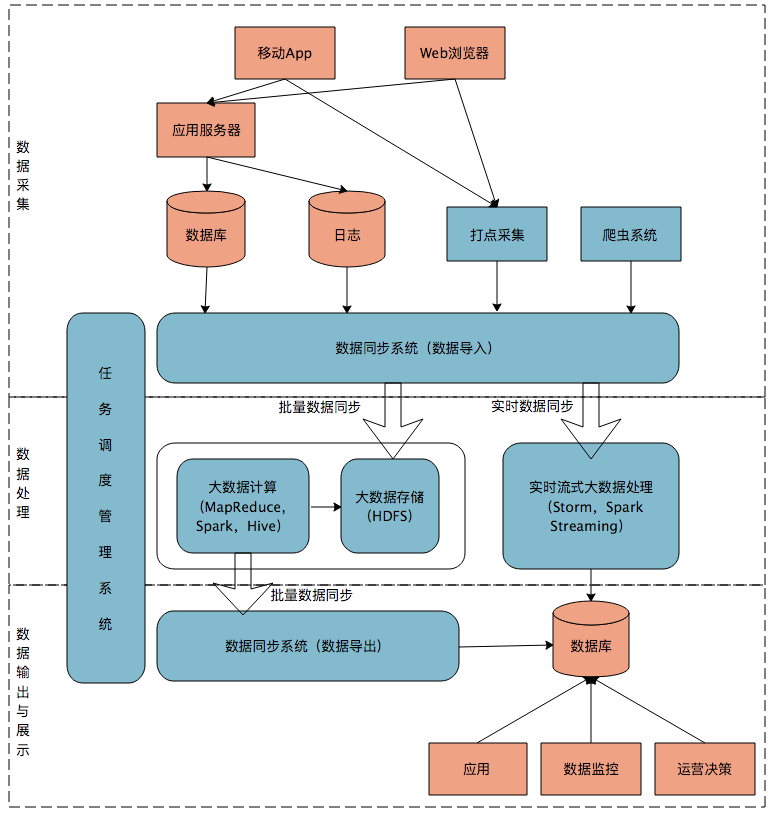
整合采集、使用与展示两端的差异,这就是大数据平台的使命
除了采集、处理、输出与展示三个主要模块之外,还需要一个任务调度系统来将三者整合起来,大数据平台上的其他系统一般都有成熟的开源软件可以选择,但是任务调度管理会涉及很多个性化的需求,通常需要团队自己开发