函数式编程
数式语言提倡在有限的几种关键数据结构(如 list 、 set 、 map )上运用针对这些数据结构高度优化过的操作,以此构成基本的运转机构以达到重用的目的。
- 命令式编程是按照“程序是一系列改变状态的命令”来建模的一种编程风格
- 函数式编程将程序描述为表达式和变换,以数学方程的形式建立模型,并且尽量避免可变的状态 一种更高层次的抽象
函数式思维的好处之一,是能够将低层次细节(如垃圾收集)的控制权移交给运行时,从而消弭了一大批注定会发生的程序错误
函数式编程几大基本操作:
- filter 过滤

- map 映射
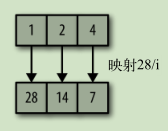
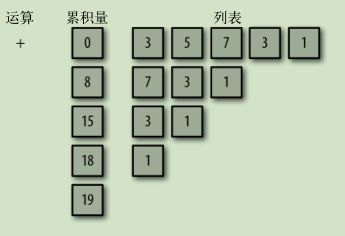
- reduce/fold 规约/折叠 用一个累积量(accumulator)来“收集”集合元素
函数式语言将一些权责让位于运行时:
- 底层迭代的权责转移到高阶函数 map filter ...
- 状态管理的权责转移到闭包 让语言自己去管理状态
- 柯里化
- 函数 process(x, y, z) 完全柯里化之后将变成 process(x)(y)(z) 的形式 这其实同工厂模式
- 部分施用
- process(x, y, z) 上部分施用一个参数,那么我们将得到还剩下两个参数的函数: process(y, z)
从迭代到递归:


尾递归:
function story() { 从前有座山,山上有座庙,庙里有个老和尚,一天老和尚对小和尚讲故事:story() // 尾递归,进入下一个函数不再需要上一个函数的环境了,得出结果以后直接返回。}
function story() { 从前有座山,山上有座庙,庙里有个老和尚,一天老和尚对小和尚讲故事:story(),小和尚听了,找了块豆腐撞死了 // 非尾递归,下一个函数结束以后此函数还有后续,所以必须保存本身的环境以供处理返回值。}
函数式语言的两种常见特性:
- 记忆 memoization
每次我们根据一组特定参数求得结果之后,就用参数值做查找用的键,把结果缓存起来。以后当函数又遇到相同参数的时候,就不需要重新计算一遍了
只有纯(pure)函数才可以适用缓存技术。纯函数是没有副作用的函数
但手动引入了缓存 往往意味着会引入更多的错误
函数式语言可以利用自身的特性很方便实现缓存
如想记忆现有的一个 (hash ) 函数,我们只要写成 (memoize (hash "homer")) ,就可以得到该函数的缓存版本
- 缓求值 lazy evaluation
尽可能地推迟求解表达式 也就是到需要时,这个值才被计算出来
在Java中 实现这个的方式可以使用很多方法,如迭代器、Stream等来实现
其他函数式编程语言则都提供了内建的工具
重用
在面向对象编程语言,复用的单元是数据结构
而函数式编程语言中 复用的单元则是操作 数据结构类型很少
函数式的重用机制就建立在列表的概念
设计模式在函数式编程语言里的应用:从根本上说,设计模式的存在意义就是弥补语言功能上的弱点
- 模板方法
class CustomerBlocks {
def plan, checkCredit, checkInventory, ship
def CustomerBlocks() {
plan = []
}
def process() {
checkCredit()
checkInventory()
ship()
}
}
面向对象编程通过封装不确定因素来使代码能被人理解;函数式编程通过尽量减少 不确定因素来使代码能被人理解
函数式编程到函数式基础设施
- 测试的真正目的是对可变事物的检验——可变的事物越多,就需要越多的测试来保证其正确性
值不可变 -> CQRS -> 函数式web编程 -> 日志数据库 -> Serverless