后端编译与优化
即时编译器
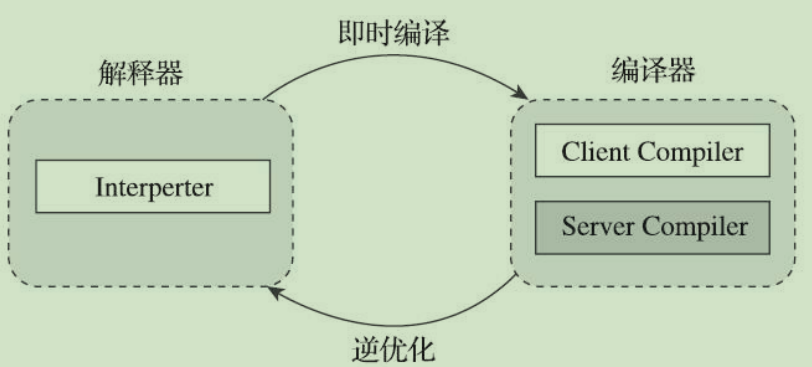
解释器与编译器
在整个Java虚拟机执行架构里,解释器与编译器经常是相辅相成地配合工作
HotSpot在JDK10之前存在两个编译器:
- C1:客户端编译器 通过 -client 参数指定使用这个编译器
- C2:服务端编译器 通过 -server 参数指定使用这个编译器
在JDK10之后 出现了一个Graal编译器 目的是用地取代C2
无论采用的编译器是C1还是C2,解释器与编译器搭配使用的方式在虚拟机中被称为“混合模式”
可以使用参数“-Xint”强制虚拟机运行于“解释模式
使用参数“-Xcomp”强制虚拟机运行于“编译模式”
分层编译根据编译器编译、优化的规模与耗时,划分出不同的编译层次,虚拟机会根据实际情况在不同层级之间转换:
分为五个层次,分为为 0 层解释执行,1 层执行没有 profiling 的 C1 代码,2 层执行部分 profiling 的 C1 代码,3 层执行全部 profiling 的 C1 代码,和 4 层执行 C2 代码
编译对象与触发条件
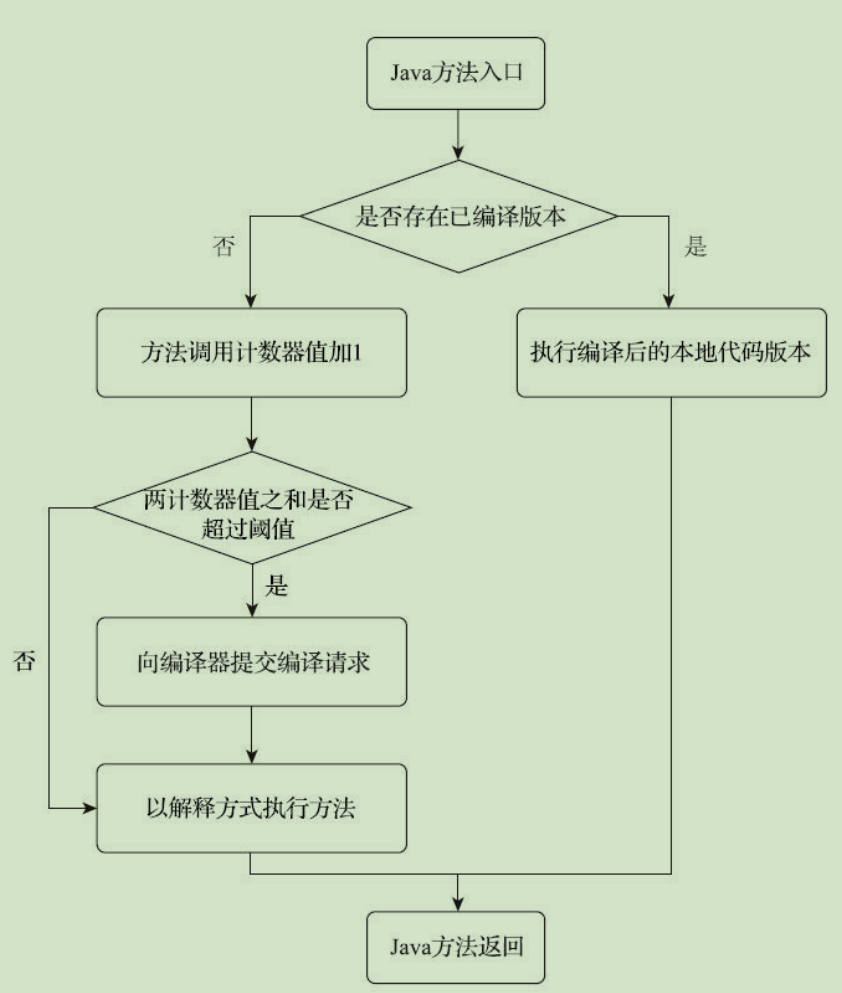
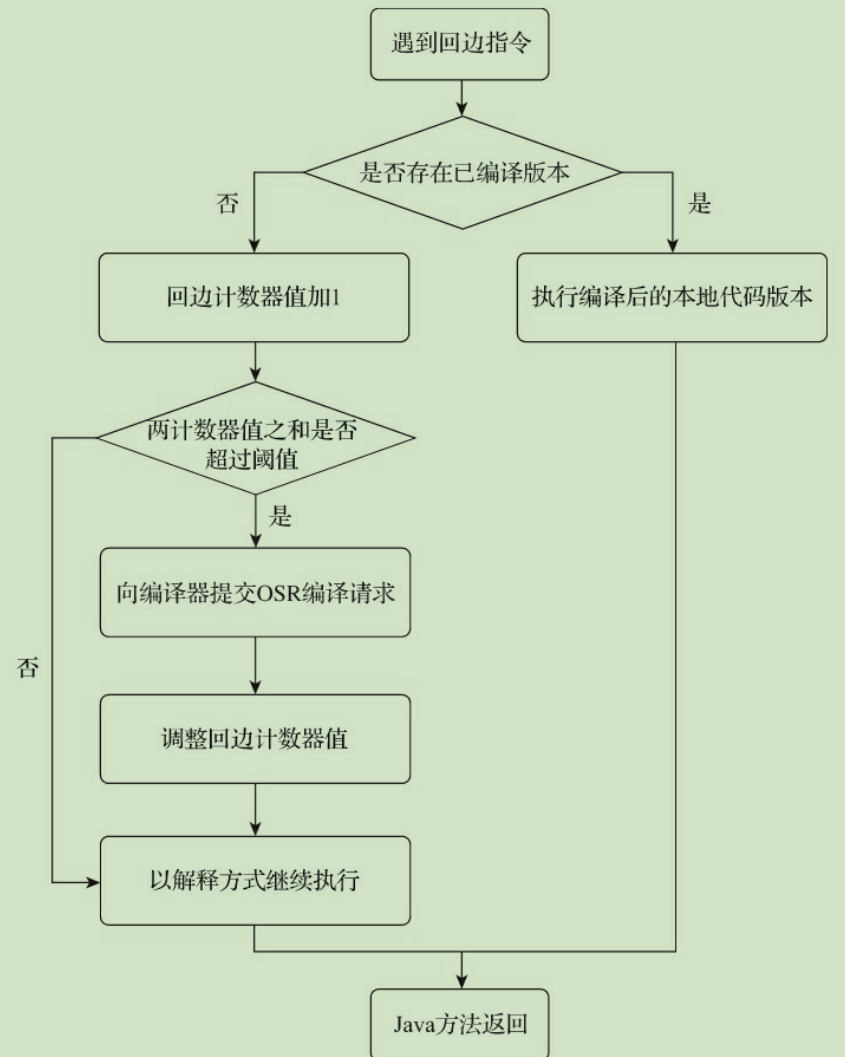
多次调用的方法以及多次执行的循环体被称为热点代码 这些热点代码会被进行编译
这两种情况编译的目标都会是方法体 第二种情况的编译方式因为编译发生在方法执行的过程中,因此被很形象地称为“栈上替换”
JVM 对于热点代码的判断称之为热点检测,目前有两种方法:
- 基于采样:采用这种方法的虚拟机会周期性地检查各个线程的调用栈顶,如果发现某个(或某些)方法经常出现在栈顶,那这个方法就是“热点方法”
- 基于计数器:采用这种方法的虚拟机会为每个方法(甚至是代码块)建立计数器,统计方法的执行次数,如果执行次数超过一定的阈值就认为它是“热点方法”
HotSpot 采用的是计数器方式 可以通过虚拟机参数-XX:CompileThreshold来人为设定这个计数器的阈值
默认设置下 HotSpot的计数器并不是绝对技术 而是一段时间内的相对计数 当这段时间一过 该方法的调用计数器就会被减少一半 称之为半衰周期 可以使用虚拟机参数-XX:-UseCounterDecay来关闭热度衰减
与方法计数器不同,回边计数器没有计数热度衰减的过程,因此这个计数器统计的就是该方法循 环执行的绝对次数
编译过程
在第一个阶段,一个平台独立的前端将字节码构造成一种高级中间代码表示(High-Level Intermediate Representation,HIR,即与目标机器指令集无关的中间表示)
在第二个阶段,一个平台相关的后端从HIR中产生低级中间代码表示(Low-Level Intermediate Representation,LIR,即与目标机器指令集相关的中间表示)
最后的阶段是在平台相关的后端使用线性扫描算法(Linear Scan Register Allocation)在LIR上分配寄存器,并在LIR上做窥孔(Peephole)优化,然后产生机器代码
intrinsic
针对特定平台架构的一种优化手段,虚拟机将为标注了@IntrinsicCandidate注解的方法额外维护一套高效实现
提前编译器
GCJ(GNU Compiler for Java)出现后提前编译基本没有什么太大进展,因为这与Java一次编译到处运行的理念相悖,直到Android 的ART的出现,也震撼到了 Java 世界
提前编译的得与失
- 传统提前编译打破的就是即时编译占用了原本给程序运行时的资源
- 提前编译的第二条路就是在给即时编译做加速
但即使编译又有以下优势:
- 性能分析制导优化(Profile-Guided Optimization,PGO),可以在运行阶段收集监控信息 从而更好地进行优化
- 激进预测性优化(Aggressive Speculative Optimization),即使编译激进优化可以做出一些假设 如果假设错了 大不了就回退到解释模式 但是提前编译不能做这些假设 它必须保证程序的外部影响优化前优化后都是一样的
- 链接时优化(Link-Time Optimization,LTO)
jaotc 提前编译
javac Main.class
jaotc --output Main.so Main.class # 将class编译为静态链接文件
java -XX:+UnlockExperimentalVMOptions -XX:AOTLibrary=./Main.so Main # 运行它
JNI
在 Java 代码中定义 native 方法之后,可以通过 javac -h命令,自动生成包含符合命名规范的 C 函数的头文件,另外一种则是可以在 C 代码中主动链接
// 主动链接
// 注:Object类的registerNatives方法的实现位于java.base模块里的C代码中
static JNINativeMethod methods[] = {
{"hashCode", "()I", (void *)&JVM_IHashCode},
{"wait", "(J)V", (void *)&JVM_MonitorWait},
{"notify", "()V", (void *)&JVM_MonitorNotify},
{"notifyAll", "()V", (void *)&JVM_MonitorNotifyAll},
{"clone", "()Ljava/lang/Object;", (void *)&JVM_Clone},
};
JNIEXPORT void JNICALL
Java_java_lang_Object_registerNatives(JNIEnv *env, jclass cls)
{
(*env)->RegisterNatives(env, cls,
methods, sizeof(methods)/sizeof(methods[0]));
}
链接完成之后就能通过 gcc 命令将其编译成为动态链接库,随后使用 System.loadLibrary 方法载入动态库
Graal
为了让 Java 虚拟机与 Graal 解耦合,我们引入了Java 虚拟机编译器接口(JVM Compiler Interface,JVMCI)
Graal 是一 Java 编写的即使编译器,其采取了一些激进的优化手段来使得编译出来的代码可以取得比 C2 更高的执行性能
编译器优化技术
方法内联
被戏称为优化之母 除了消除方法调用的成本之外,它更重要的意义是为其他优化手段建立良好的基础
在 Java 中,基本所有对象的方法都是虚方法,也就是这些方法直到运行时才能确定被调用的是哪一个,这为方法内联带来了困难
为了解决虚方法的内联问题,Java虚拟机首先引入了一种名为类型继承关系分析(Class HierarchyAnalysis,CHA)的技术用于确定在目前已加载的类中,某个接口是否有多于一种的实现、某个类是否存在子类、某个子类是否覆盖了父类的某个虚方法等
如果CHA也判断方法有多个版本 那么会进入最后一次内联缓存优化尝试
总而言之,多数情况下Java虚拟机进行的方法内联都是一种激进优化
逃逸分析
是为其他优化措施提供依据的分析技术
分析对象动态作用域,当一个对象在方法里面被定义后,它可能被外部所引用 逃逸级别从低到高:
- 不逃逸
- 方法逃逸:通过方法返回值或者参数逃逸到其他方法
- 线程逃逸:被其他线程访问到
- 部分逃逸:Graal 可以通过分析控制流来发现对象能否逃逸
根据这些逃逸级别,可以采取不同的优化手段:
- 栈上分配 如果对象不会方法逃逸 那对象可在栈内存分配 随着方法栈弹出,内存也被回收 大大减少GC的压力
- 标量替换 如果对象不会方法逃逸,将对对象的访问转换为对int long的标量类型的访问 或者将对象创建打散为各种基本数据类型的创建
- 同步消除 如果能确定不会线程逃逸 那就可以去掉同步机制 提高性能
公共子表达式消除
如果一个表达式E之前已经被计算过了,并且从先前的计算到现在E中所有变量的值都没有发生变化,那么E的这次出现就称为公共子表达式。对于这种表达式,没有必要花时间再对它重新进行计算,只需要直接用前面计算过的表达式结果代替E
字段访问优化
- 读取优化:即时编译器将沿着控制流缓存字段存储、读取的值,并在接下来的字段读取操作时直接使用该缓存值
- 存储优化:如果一个字段的两次存储之间没有对该字段的读取操作、方法调用以及内存屏障,那么即时编译器可以将第一个冗余的存储操作给消除掉
- 死代码消除:消除掉冗余的存储、不可达的分支
循环优化
- 循环无关代码外提:在不改变程序语义的情况下,将循环无关代码提出循环之外
- 循环展开:在循环体中重复多次循环迭代,并减少循环次数的编译优化
- 循环判断外提:将循环中的 if 语句外提至循环之前,并且在该 if 语句的两个分支中分别放置一份循环代码
- 循环剥离:循环的前几个迭代或者后几个迭代都包含特殊处理。通过将这几个特殊的迭代剥离出去,可以使原本的循环体的规律性更加明显,从而触发进一步的优化
向量化
CPU 提供的 SIMD 指令只能被 @IntrinsicCandidate 的方法使用,自动向量化能够针对展开的计数循环,进行向量化优化
数组边界检查消除
使用隐式异常来优化如数组边界检查以及NPE判断等每次操作的成本,用Java伪代码代表如下:
try {
return a[i]
} catch(Exception e){
// 使用进程级别的Segment Fault信号的异常处理器处理这个异常
}