容器化
namespace
- 一种隔离机制,主要目的是隔离运行在同一个宿主机上的容器,让这些容器之间不能访问彼此的资源
作用:充分地利用系统的资源,在同一台宿主机上可以运行多个用户的容器;保证了安全性,不同用户之间不能访问对方的资源
cgroups
对指定的进程做各种计算机资源的限制
- v1: 每个进程在各个 cgroups 子系统中独立配置,可以属于不同的 group
- v2: 各个子系统可以协调统一地管理资源
容器进程
1号进程与信号
- 容器中,1 号进程永远不会响应 SIGKILL 和 SIGSTOP 这两个特权信号,即kill -9 1 在容器中是不工作的
- 对于 SIGTERM 信号,如果用户的1号进程自己注册了 handler,那么可以响应 kill 1
僵尸进程
- 父进程在创建完子进程之后就不管了,这就是造成子进程变成僵尸进程的原因
两个系统调用可以回收掉僵尸进程:
- wait() 如果没有僵尸子进程会一直阻塞
- waitpid() 如果没有僵尸子进程可以直接返回
进程停止
Docker 停止一个容器,会向容器的 init 进程发送一个 SIGTERM 信号,在 init 进程退出之后,容器内的其他进程也都立刻退出,其他进程收到的是 SIGKILL 信号
当 Linux 进程收到 SIGTERM 信号并且使进程退出,这时 Linux 内核对处理进程退出的入口点就是 do_exit() 函数,do_exit() 函数中会释放进程的相关资源,比如内存,文件句柄,信号量等,做完这些工作之后,它会调用一个 exit_notify() 函数,用来通知和这个进程相关的父子进程等
为了让子进程也能收到 SIGTERM 信号,init进程可以捕获 SIGTERM 信号,然后调用kill转发给子进程
容器CPU
CPU usage
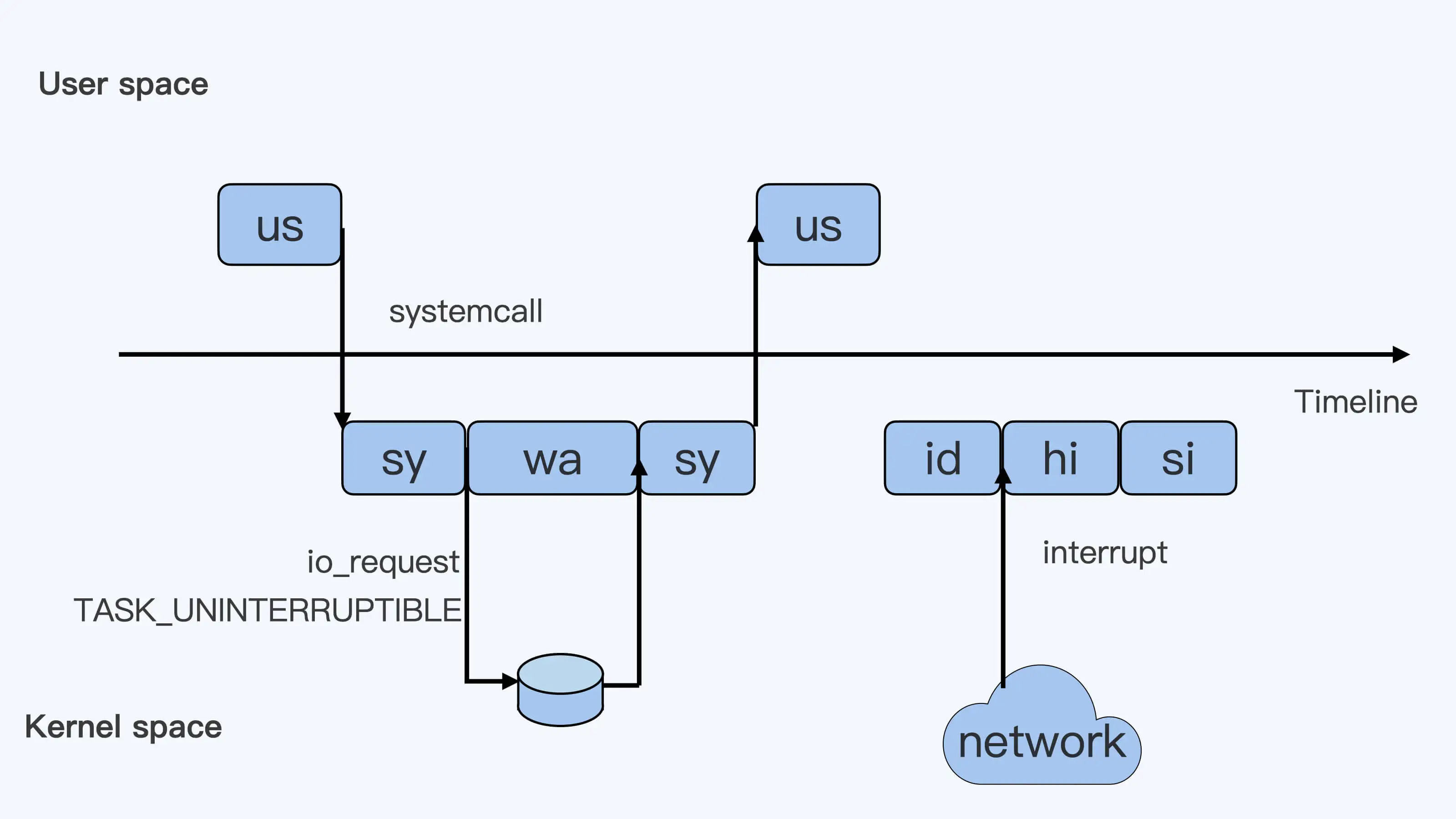
| 类型 | 具体含义 |
|---|---|
| us | User,用户态CPU时间,不包括低优先级进程的用户态时间(nice值 1-19 ) |
| sys | System,内核态CPU时间 |
| ni | Nice, nice 值1 -19的进程用户态CPU时间 |
| id | ldle,系统空闲CPU时间 |
| wa | lowait,系统等待I/O的CPU时间,这个时间不计入进程CPU时间 |
| hi | Hardware irq,处理硬中断的时间,这个时间不计入进程CPU时间 |
| si | Softirq,处理软中断的时间,这个时间不计入进程CPU时间 |
| st | Steal,表示同一个宿主机上的其他虚拟机抢走的CPU时间 |
在 k8s 中,通过limit可以限制CPU的使用
CPU cgroup:
- cpu.cfs_period_us,它是 CFS 算法的一个调度周期
- pu.cfs_quota_us,它“表示 CFS 算法中,在一个调度周期里这个控制组被允许的运行时间
- cpu.shares,控制组之间的 CPU 分配比例,它的缺省值是 1024
cpu.cfs_quota_us 和 cpu.cfs_period_us 这两个值决定了每个控制组中所有进程的可使用 CPU 资源的最大值,cpu.shares 这个值决定了 CPU Cgroup 子系统下控制组可用 CPU 的相对比例
每个进程的 CPU Usage 只包含用户态(us 或 ni)和内核态(sy)两部分,其他的系统 CPU 开销并不包含在进程的 CPU 使用中
CPU使用率
在 /proc/[pid]/stat 下有 utime 和 stime:
- utime:表示进程的用户态部分在 Linux 调度中获得 CPU 的 ticks
- 表示进程的内核态部分在 Linux 调度中获得 CPU 的 ticks
$$进程的 ticks = 时间点2(utime + stime) - 时间点1(utime + stime)$$
$$进程的 CPU 使用率 =(进程的 ticks/ 单个 CPU 总 ticks)*100.0$$
对于系统的 CPU 使用率,需要读取 /proc/stat 文件,得到瞬时各项 CPU 使用率的 ticks 值,相加得到一个总值,单项值除以总值就是各项 CPU 的使用率
也可以从每个容器的 CPU Cgroup 控制组里的 cpuacct.stat 的统计值中得到整个容器的 CPU 使用率
load average
统计了这两种情况的进程:
- Linux 进程调度器中可运行队列(Running Queue)一段时间(1 分钟,5 分钟,15 分钟)的进程平均数
- Linux 进程调度器中休眠队列(Sleeping Queue)里的一段时间的 TASK_UNINTERRUPTIBLE 状态下的进程平均数
Load Average = 可运行队列进程平均数 + 休眠队列中不可打断的进程平均数
处于 D 状态(主要集中在 disk I/O 的访问和信号量(Semaphore)锁的访问)的进程即休眠队列中不可打断的进程过多就会增加负载,这是性能下降的表现
容器内存
OOM
在 Linux 系统里如果内存不足时,就需要杀死一个正在运行的进程来释放一些内存,内核里有一个 oom_badness() 函数用来计算进程被杀死的几率:
系统总的可用页面数乘以进程的 OOM 校准值 oom_score_adj,再加上进程已经使用的物理页面数
oom_score_adj 保存在 /proc/[pid]/oom_score_adj
memeroy cgroup
- memory.limit_in_bytes:控制组里所有进程可使用内存的最大值
- memory.oom_control:决定内存到达上限时,要不要触发 OOM killer,如果关闭killer,内存满时其他申请内存的进程会处于一个停止状态
- memory.usage_in_bytes:只读,当前控制组里所有进程实际使用的内存总和
RSS与PageCache
- RSS:Resident Set Size,指进程真正申请到物理页面的内存大小,包含了进程的代码段内存,栈内存,堆内存,共享库的内存, 这些内存是进程运行所必须的
- PageCache:提高磁盘文件读写性能而利用空闲物理内存的机制
Memory Cgroup 控制组里 RSS 内存和 Page Cache 内存的和,正好是 memory.usage_in_bytes 的值
要判断容器真实的内存使用量,不能用Memory Cgroup 里的 memory.usage_in_bytes,而需要用 memory.stat 里的 rss 值
memory.usage_in_bytes = memory.stat[rss] + memory.stat[cache] + memory.kmem.usage_in_bytes
swap
- swappiness参数:值的范围是 0 到 100,用来定义 Page Cache 内存和匿名内存的释放的一个比例
值为 100 的时候系统平等回收匿名内存和 Page Cache 内存;一般缺省值为 60,就是优先回收 Page Cache;即使 swappiness 为 0,也不能完全禁止 Swap 分区的使用,就是说在内存紧张的时候,也会使用 Swap 来回收匿名内存
在 memory cgroup 中,当 memory.swappiness = 0 的时候,对匿名页的回收是始终禁止的,也就是始终都不会使用 Swap 空间
容器存储
容器文件系统
为了减少相同镜像文件在同一个节点上的数据冗余,可以节省磁盘与下载带宽开销,使用容器文件系统,UnionFS:主要功能是把多个目录(处于不同的分区)一起挂载(mount)在一个目录下
OverlayFS是UnionFS的一种实现:

在merged做文件操作:
- 新建文件,这个文件会出现在 upper/ 目录中
- 删除文件,如果删除upper目录里的文件,文件会直接消失,如果删除lower里,会通过在upper目录中增加了一个特殊文件来告诉 OverlayFS 文件已被删除
- 修改文件同删除文件,如果修改upper里的文件,就可以直接修改,如果修改lower里的,则会在upper中创建一个新的替代旧的
Docker 容器镜像文件可以分成多个层(layer),每层可以对应 OverlayFS 里 lowerdir 的一个目录,lowerdir 支持多个目录,也就可以支持多层的镜像文件
容量限制
在容器中对于 OverlayFS 中写入数据,其实就是往宿主机的一个目录(upperdir)里写数据
Linux 系统里的 XFS 文件系统缺省都有 Quota 的特性,可以用来限制写入文件系统的文件总量
Docker 可以通过加上一个参数 --storage-opt size=xxx 使用这个特性
blkio cgroup v1
- blkio.throttle.read_iops_device:磁盘读取 IOPS 限制
- blkio.throttle.read_bps_device:磁盘读取吞吐量限制
- blkio.throttle.write_iops_device:磁盘写入 IOPS 限制
- blkio.throttle.write_bps_device:磁盘写入吞吐量限制
IOPS 是 Input/Output Operations Per Second 的简称,也就是每秒钟磁盘读写的次数,吞吐量(Throughput)是指每秒钟磁盘中数据的读取量,一般以 MB/s 为单位
吞吐量 = 数据块大小 *IOPS
v1的blkio cgroup只能限制direct IO,即直接IO读写的场景,无法限制buffered IO读写经过内存缓冲的场景,Linux 里,由于考虑到性能问题,绝大多数的应用都会使用 Buffered I/O 模式
cgroup v2
v2 相比 v1 做的最大的变动就是一个进程属于一个控制组,而每个控制组里可以定义自己需要的多个子系统
打开 v2 的方法就是配置一个 kernel 参数"cgroup_no_v1=blkio,memory",这表示把 Cgroup v1 的 blkio 和 Memory 两个子系统给禁止,这样 Cgroup v2 的 io 和 Memory 这两个子系统就打开了
IO与PageCache
如果容器在做内存限制的时候,Cgroup 中 memory.limit_in_bytes 设置得比较小,而容器中的进程又有很大量的 I/O,这样申请新的 Page Cache 内存的时候,又会不断释放老的内存页面,这些操作就会带来额外的系统开销
对于控制page cache 有如下参数:
- dirty_background_ratio / dirty_background_bytes:如果脏页的内存 占比/数值 达到这个值,内核 flush 线程就会把脏页刷到磁盘里
- dirty_ratio / dirty_bytes:如果脏页内存 占比/数值 达到这个值,这时候正在执行 Buffered I/O 写文件的进程就会被阻塞住,直到它写的数据页面都写到磁盘为止
- dirty_writeback_centisecs:时间值,以百分之一秒为单位,缺省值是 500,也就是 5 秒钟。它表示每 5 秒钟会唤醒内核的 flush 线程来处理脏页
- dirty_expire_centisecs:时间值,以百分之一秒为单位,缺省值是 3000,也就是 30 秒钟。它定义了 dirty page 在内存中存放的最长时间,如果一个脏页超过这里定义的时间,那么内核的 flush 线程也会把这个页面写入磁盘
容器网络
docker 可以通过在启动容器时传递 –sysctl 参数来修改 / proc/sys/net 里面的配置参数
docker exec、kubectl exec、ip netns exec、nsenter 等命令原理相同,都是基于 setns 系统调用,切换至指定的一个或多个 namespace(s)
network namespace
资源,不同的namspace是隔离的:
- 网络设备,这里指的是 lo,eth0 等网络设备
- IPv4 和 IPv6 协议栈,IP 层以及上面的 TCP 和 UDP 协议栈也是独立工作的
- IP 路由表
- 防火墙规则,就是 iptables 规则
- 网络的状态信息
操作:
- clone():建立出来一个新的进程,这个新的进程所在的 Network Namespace 也是新的
- unshare():接改变当前进程的 Network Namespace
容器网络配置
想让数据从容器 Netowrk Namespace 发送到 Host Network Namespace,可以用配置一对 veth 虚拟网络设备的方法实现。而让数据包从宿主机的 eth0 发送出去,就用可 bridge+nat 的方式完成
容器通常缺省使用 veth 虚拟网络接口,不过 veth 接口会有比较大的网络延时,在对外发送数据的时候,peer veth 接口都会 raise softirq 来完成一次收包操作,这样就会带来数据包处理的额外开销
如果要降低处理开销,使用ipvlan/macvlan 的网络接口,这两个直接在物理网络接口上虚拟出接口,在发送对外数据包的时候可以直接通过物理接口完成,没有节点内部类似 veth 的那种 softirq 的开销,但对于需要使用 iptables 规则的容器就不能工作了
通过 veth 接口从容器向外发送数据包,会触发 peer veth 设备去接收数据包,这个接收的过程就是一个网络的 softirq 的处理过程,在缺省的状况下(也就是没有 RPS 的情况下),enqueue_to_backlog() 把数据包放到了“当前运行的 CPU”(get_cpu())对应的数据队列中,这回增加发送数据出现乱序的几率导致 TCP 的快速重传
为了解决这个问题,如果配置网卡的RSS(Receive Side Scaling),get_cpu()就会变成get_rps_cpu(),每个硬件中断可以由一个 CPU 来处理,可以保证一个 TCP 流的数据始终在一个 RX 队列中
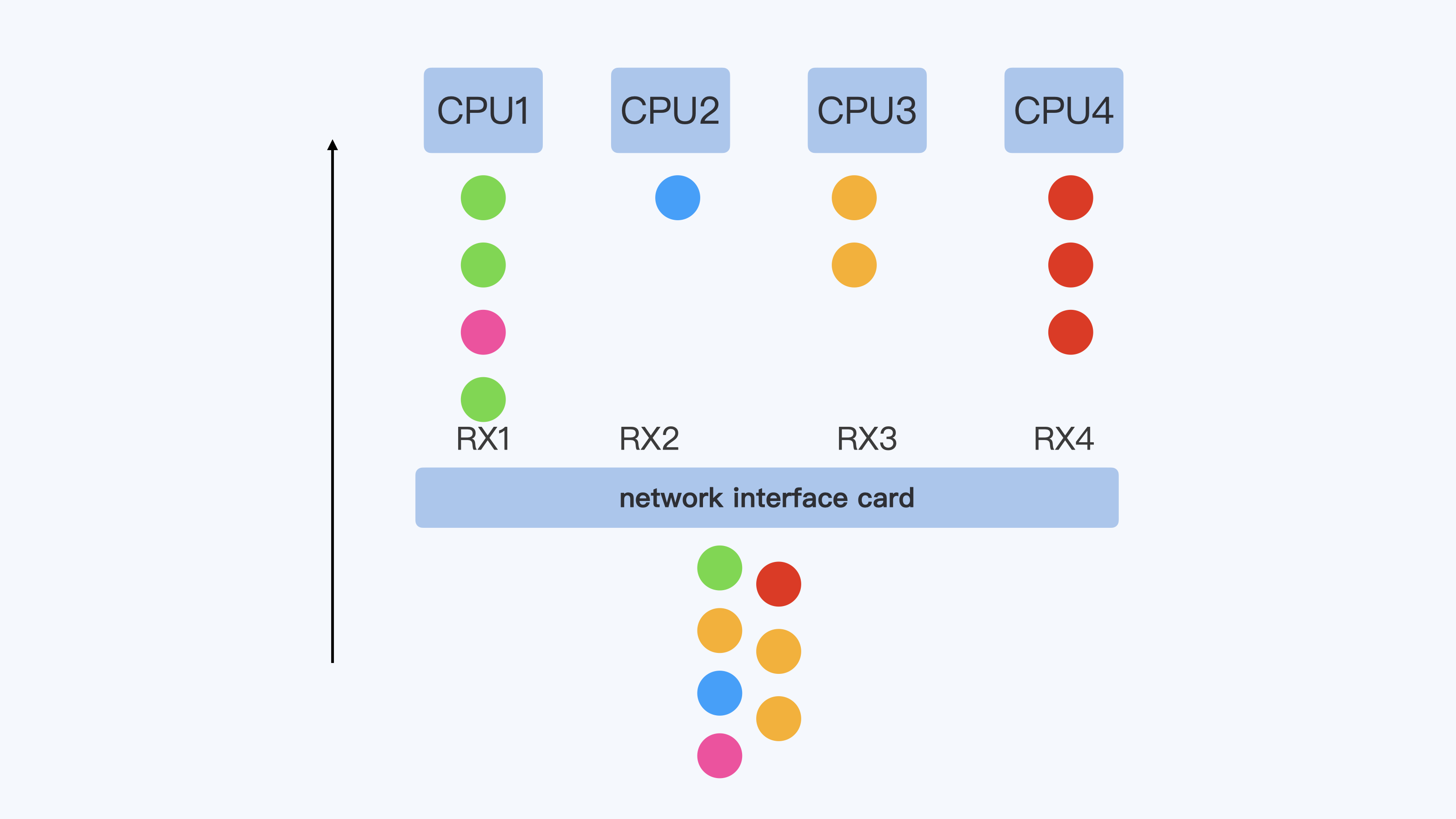
RPS(Receive Packet Steering)其实就是在软件层面实现类似的功能,通过对数据包四元素计算hash值,决定要分配到哪个CPU上,但RPS 的配置还是会带来额外的系统开销
容器安全
Linux capabilities
Linux capabilities 把 Linux root 用户原来所有的特权做了细化,可以更加细粒度地给进程赋予不同权限
对于任意一个进程,在做任意一个特权操作的时候,都需要有这个特权操作对应的 capability,普通 Linux 节点上,非 root 用户启动的进程缺省没有任何 Linux capabilities,而 root 用户启动的进程缺省包含了所有的 Linux capabilities
文件中可以设置 capabilities 参数值,并且这个值会影响到最后运行它的进程
- setcap
- getcap
容器 root 用户默认只赋予了 15 个 capabilities,启动时如果加上 privileged 参数则会包含所有的 Linux capabilities
容器指定用户
在启动时可以指定一个 -u 参数来指定容器的用户的uid
由于用户 uid 是整个节点中共享的,那么在容器中定义的 uid,也就是宿主机上的 uid,这样就很容易引起 uid 的冲突,每个用户下的资源是有限制的,共享的资源如果使用共享的用户很快就会消耗光这个uid下的资源
user namespace
Namespace 中的 uid/gid 的值与宿主机上的 uid/gid 值建立了一个映射关系。经过 User Namespace 的隔离,我们在 Namespace 中看到的进程的 uid/gid,就和宿主机 Namespace 中看到的 uid 和 gid 不一样
Docker 通过配置 daemon 使其创建默认的用户用于 user namespace
这样可以把容器中 root 用户(uid 0)映射成宿主机上的普通用户,同时对于用户在容器中自己定义普通用户 uid 的情况,我们只要为每个容器在节点上分配一个 uid 范围,就不会出现在宿主机上 uid 冲突的问题了
rootless container
指容器中以非 root 用户来运行进程,还指以非 root 用户来创建容器,管理容器。也就是说,启动容器的时候,Docker 或者 podman 是以非 root 用户来执行的